i've written a small parser to get the content of 5 web-pages, i run it and it executes without error and give me Process finished with exit code 0, but nothing happens – i have a writer within the script that should create a .csv and write the data there, but my script has no output, it just executes and terminates in silence with exit code 0. have never encountered such thing, any ideas?
the structure of the web-page is like that - the tag row mb-2 contains all div tags with listings:
<div >
<div ></div>
<div ></div>
<div ></div>
<div ></div>
</div>
the code of the script looks like that:
import requests
import csv
from bs4 import BeautifulSoup as bs
u_list = ['https://www.landcentury.com/search/page-1?categories[0]=commercial-and-industrial-land&options[0]=for-sale',
'https://www.landcentury.com/search/page-2?categories[0]=commercial-and-industrial-land&options[0]=for-sale',
'https://www.landcentury.com/search/page-3?categories[0]=commercial-and-industrial-land&options[0]=for-sale',
'https://www.landcentury.com/search/page-4?categories[0]=commercial-and-industrial-land&options[0]=for-sale',
'https://www.landcentury.com/search/page-5?categories[0]=commercial-and-industrial-land&options[0]=for-sale']
for url in range(0, 5):
page = requests.get(u_list[url])
soup = bs(page.content, 'html.parser')
landplots = soup.find_all('div', class_='row mb-2')
for l in landplots:
row = []
try:
plot_price = l.find('div', class_= 'price ').find_next(text=True).get_text(strip=True)
plot_location = l.find('div', class_ = 'card-title').find_next(text=True).text
plot_square = l.find('div', class_ = 'card-title').find_next(text=True).get_text(strip=True)
row.append(plot_price)
row.append(plot_location)
row.append(plot_square)
print(plot_price)
print(plot_square)
print(plot_location)
print()
except AttributeError:
continue
with open("parsing_second.csv", 'a', newline = '') as f:
writer = csv.writer(f)
writer.writerow(row)
CodePudding user response:
As I understand it, you need fields - price, square and location. I suggest using Pandas to save to a file. This will allow you more flexibility in choosing the format in the future.
import requests
from bs4 import BeautifulSoup
import pandas as pd
results = []
for page in range(0, 5):
url = f'https://www.landcentury.com/search/page-{page}?categories[0]=commercial-and-industrial-land&options[0]=for-sale'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
for card in soup.find_all('div', class_='listing-item'):
price = card.find('div', class_='price').getText(separator=' ').strip()
square, location = card.find('div', class_='card-title').getText(separator='/').split('/')
data = {
'Price': price,
'Square': square,
'Location': location
}
results.append(data)
df = pd.DataFrame(results)
df.to_csv('landcentury.csv', index=False)
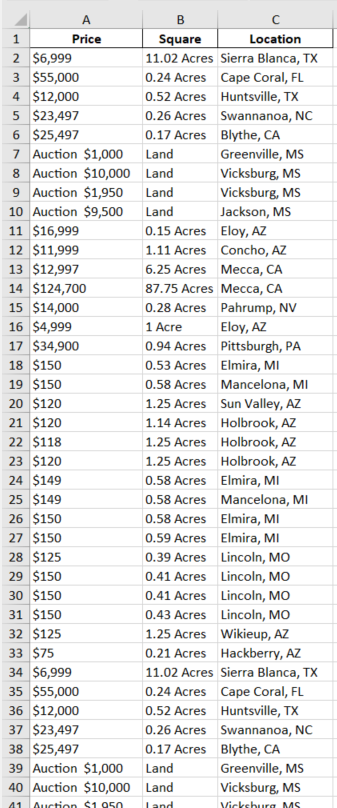
CSV RESULT: