'''I'm unable to scrape ingredients from table with my code. Please help me with my code. I want only ingredients name as a output. I've also provided the image of ingredients table. Here, I only want the ingredients names marked with a red circle.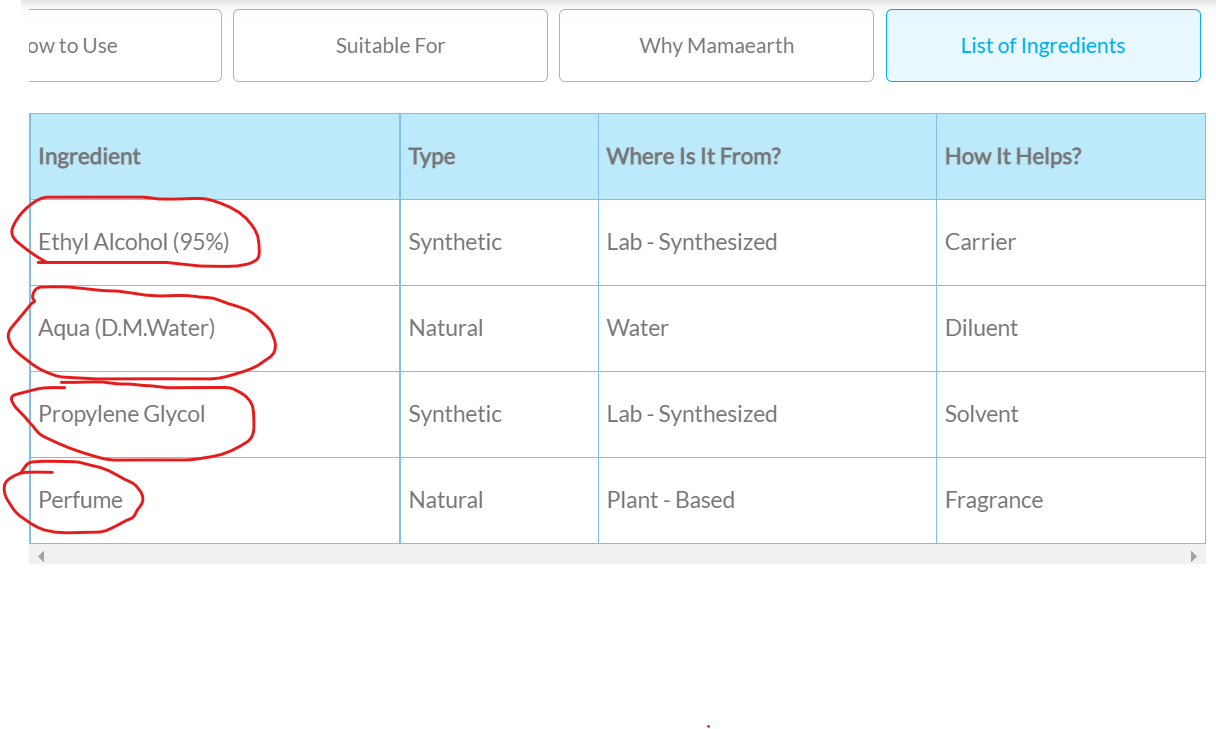 '''
'''
url=https://mamaearth.in/product/mamaearth-me-deo-for-a-scent-that-s-unique-to-you-120-ml
table1 = soup.find('div', class_='CmsItemRevamp-sc-1moss4z-0 eQqUUy CMSContent').text.strip()
table1
mydata = pd.DataFrame(columns = headers)
for j in table1.find_all('tr')[1:]:
row_data = j.find_all('td')
row = [i.text for i in row_data]
length = len(mydata)
mydata.loc[length] = row
CodePudding user response:
The information is in the HTML, but it is rendered using Javascript. As such you need to extract it yourself from JSON contained inside a <script> section of the HTML.
This could be done as follows:
from bs4 import BeautifulSoup
import requests
import json
url= "https://mamaearth.in/product/mamaearth-me-deo-for-a-scent-that-s-unique-to-you-120-ml"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
script_text = soup.find('script', id="__NEXT_DATA__").string
data = json.loads(script_text)
soup_product = BeautifulSoup(data['props']['initialProps']['pageProps']['cmsContent'][5]['content'], "html.parser")
for tr in soup_product.find_all('tr'):
print(tr.td.get_text(strip=True)) # display just the first td element
I suggest you print(data) to see all the available information that is returned. The hardest part is finding the location inside the JSON structure for what you need.
This would give you the following output:
Ingredient
Ethyl Alcohol (95%)
Aqua (D.M.Water)
Propylene Glycol
Perfume
Note: Some of the JSON values contain HTML which is why a second call to BeautifulSoup is used to parse this embedded HTML.
An alternative approach would be to use something like selenium to control your browser. This would render the HTML as you see when using view source. The downside is it is MUCH slower and resource intensive.
To output the ingredients on one line:
ingredients = [tr.td.get_text(strip=True) for tr in soup_product.find_all('tr')][1:] # [1:] to skip header
print(','.join(ingredients))