I'm using SQL Queries for the first time and learning it. I've got a table like this:
| yearName | productcompanyID |
|---|---|
| 2001 | ID 1 |
| 2001 | ID 1 |
| 2001 | ID 2 |
| 2001 | ID 1 |
| 2001 | ID 1 |
| 2002 | ID 1 |
| 2002 | ID 1 |
| 2002 | ID 2 |
| 2002 | ID 2 |
| 2003 | ID 2 |
And I would like to count how many times a productcompanyID appear but counting it only once for a year. (Sorry my English is not my language and I might not be clear)
What I mean, for the moment I've writtent this SQL:
SELECT DISTINCT(productcompanyid),
COUNT(productcompanyid)
FROM mydatabase
GROUP BY productcompanyid
And it gives me the result as ID 1: 6 and ID 2 : 4.
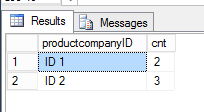
What I would like to have is ID 1 : 2 (as it appears at least once in year 2001 and year 2002) and ID 2: 3 (as it appears at least once in year 2001, year 2002 and year 2003)
Thanks for your help.
CodePudding user response:
You actually need to combine count and distinct, something like this:
select productcompanyID, count(distinct yearName) as distinctYears
from mydatabase
group by productcompanyID
CodePudding user response:
The simplest query and have some additional performance are using 2 level aggregation, somethings as follow:
--create temp table named #table1 and add row1
select 2001 yearName, 'ID 1' productcompanyID into #table1
--add remaining rows to #table1
insert into #table1
select 2001, 'ID 1' union all
select 2001, 'ID 2' union all
select 2001, 'ID 1' union all
select 2001, 'ID 1' union all
select 2002, 'ID 1' union all
select 2002, 'ID 1' union all
select 2002, 'ID 2' union all
select 2002, 'ID 2' union all
select 2003, 'ID 2'
--/query to count how many times a productcompanyID appear each a year*/
select productcompanyID, count(1) cnt
from (
select yearName, productcompanyID
from #table1
group by yearName, productcompanyID
)a
group by productcompanyID
It should give the result as what you asking on the question.