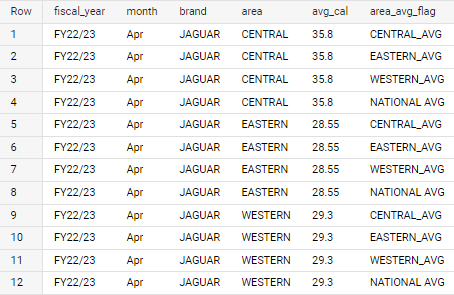
I have a big query SQL table like the below, consider this an example only:

want output like below:
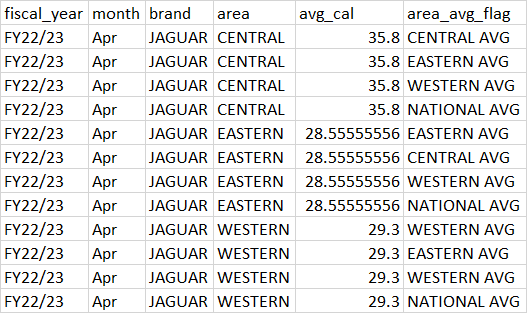
I tried using cross join but seems like it doesn't work.
SELECT a.* from `table1` a, `table2` b
where a.area_avg_flag = b.area_avg_flag
CodePudding user response:
A cross join would work for you. You can try something like:
WITH
dummy_data as
(
SELECT 'FY22/23' AS fiscal_year, 'Apr' as month, 'JAGUAR' as brand, 'CENTRAL' as area, 35.8 as avg_cal, 'CENTRAL_AVG' as area_avg_flag UNION ALL
SELECT 'FY22/23' AS fiscal_year, 'Apr' as month, 'JAGUAR' as brand, 'EASTERN' as area, 28.55 as avg_cal, 'CENTRAL_AVG' as area_avg_flag UNION ALL
SELECT 'FY22/23' AS fiscal_year, 'Apr' as month, 'JAGUAR' as brand, 'WESTERN' as area, 29.3 as avg_cal, 'CENTRAL_AVG' as area_avg_flag
)
SELECT table1.* except(area_avg_flag), area as area_avg_flag
FROM dummy_data as table1
CROSS JOIN UNNEST(['CENTRAL AVG', 'EASTERN AVG', 'WESTERN AVG', 'NATIONAL AVG']) as area
CodePudding user response:
Consider also
select t.* replace(_area as area_avg_flag)
from your_table t,
unnest(array(select distinct area_avg_flag from your_table) || ['NATIONAL AVG']) _area
if applied to sample data in your question - output is