I'm trying to read a specific region on a PDF file. How to do it?
I've tried:
- Using PyPDF2, cropped the PDF page and read only that. It doesn't work because PyPDF2's cropbox only shrinks the "view", but keeps all the items outside the specified cropbox. So on reading the cropped pdf text with extract_text(), it reads all the "invisible" contents, not only the cropped part.
- Converting the PDF page to PNG, cropping it and using Pytesseract to read the PNG. Py tesseract doesn't work properly, don't know why.
CodePudding user response:
PyMuPDF can probably do this.
I just answered another question regarding getting the "highlighted text" from a page, but the solution uses the same relevant parts of the PyMuPDF API you want:
- figure out a rectangle that defines the area of interest
- extract text based on that rectangle
and I say "probably" because I haven't actually tried it on your PDF, so I cannot say for certain that the text is amenable to this process.
import os.path
import fitz
from fitz import Document, Page, Rect
# For visualizing the rects that PyMuPDF uses compared to what you see in the PDF
VISUALIZE = True
input_path = "test.pdf"
doc: Document = fitz.open(input_path)
for i in range(len(doc)):
page: Page = doc[i]
page.clean_contents() # https://pymupdf.readthedocs.io/en/latest/faq.html#misplaced-item-insertions-on-pdf-pages
# Hard-code the rect you need
rect = Rect(0, 0, 100, 100)
if VISUALIZE:
# Draw a red box to visualize the rect's area (text)
page.draw_rect(rect, width=1.5, color=(1, 0, 0))
text = page.get_textbox(rect)
print(text)
if VISUALIZE:
head, tail = os.path.split(input_path)
viz_name = os.path.join(head, "viz_" tail)
doc.save(viz_name)
For context, here's the project I just finished where this was working for the highlighted text, 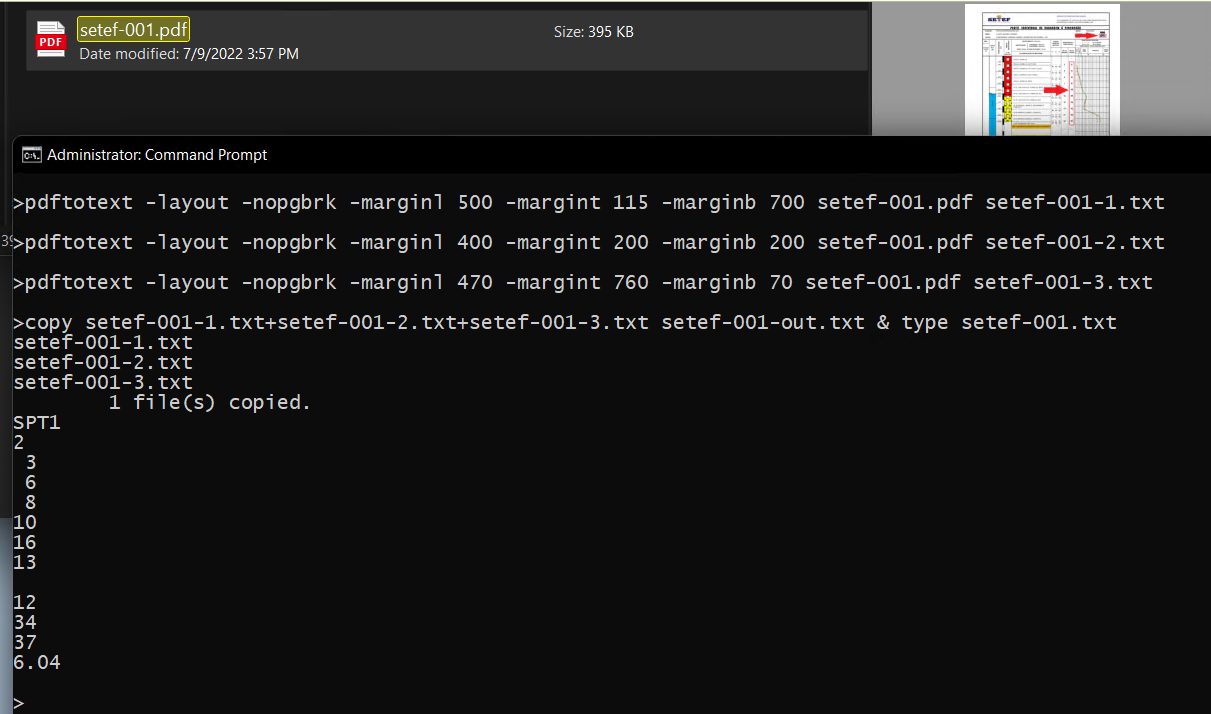
CodePudding user response:
Using Zach Young's answer, this is the final code:
def get_data():
# INPUT
pdf_in = '_SPTs.pdf'
# Rectangles defining data to be extracted
furo_rect = Rect(506, 115, 549, 128)
spt_rect = Rect(388, 201, 422, 677)
na_rect = Rect(464, 760, 501, 767)
# fitz Document
doc: Document = fitz.open(pdf_in)
# Pages loop
spt_data = []
for i in range(len(doc)):
page: Page = doc[i]
furo = page.get_textbox(furo_rect)
spt = page.get_textbox(spt_rect).splitlines()
na = page.get_textbox(na_rect)
spt_data.append([furo, spt, na])
print(f'Furo: {furo} | SPT: {spt} | NA: {na}')
# Export values to Excel with some data handling
workbook = xlsxwriter.Workbook('_SPTs_pymu.xlsx')
worksheet = workbook.add_worksheet()
for i,data in enumerate(spt_data):
worksheet.write(i, 0, data[0])
for j in range(len(data[1])):
try:
spt_value = float(data[1][j])
except:
if data[1][j] == '-':
spt_value = 0
else:
spt_value = data[1][j]
worksheet.write(i,j 1,spt_value)
try:
na_value = float(data[2])
except:
na_value = data[2]
worksheet.write(i,19,na_value)
workbook.close()
return