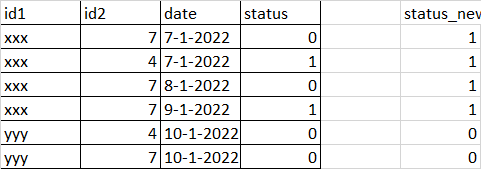
In a dataframe I have the ids and status in different dates. For a particular day,id1,id2, If the status is 1, I need to update previous two days status to 1. Dataframe is provided below I need to get the status_new from status column
data recreation code is below:
import pandas as pd
data=pd.DataFrame(data=[["xxx",7,"7-1-2022",0],["xxx",4,"7-1-2022",1],["xxx",7,"8-1-2022",0],["xxx",7,"9-1-2022",1],["yyy",4,"10-1-2022",0],["yyy",7,"10-1-2022",0]],columns=["id1","id2","date","status"])
I tried with below code, but it doesn't worked.
df['date']=pd.to_datetime(df['date']).dt.date
grouped=df.groupby([id1,id2])['date']
df['status']= grouped.shift().dt.date.where(grouped.diff().dt.days<3,df['status'])
CodePudding user response:
If datetimes are consecutive withjout duplicates per groups use:
df['date'] = pd.to_datetime(df['date'], dayfirst=True)
df = df.sort_values(['id1','id2','date'], ascending=[True, True, False])
df['status'] = df['status'].mask(df['status'].eq(0))
df['status'] = df.groupby(['id1','id2'])['status'].ffill(limit=2).fillna(0).astype(int)
df = df.sort_index()
print (df)
id1 id2 date status
0 xxx 7 2022-01-07 1
1 xxx 4 2022-01-07 1
2 xxx 7 2022-01-08 1
3 xxx 7 2022-01-09 1
4 yyy 4 2022-01-10 0
5 yyy 7 2022-01-10 0
If possible some non consecutive datetimes solution is possible with resample of maximal values per groups and days:
print (df)
id1 id2 date status
0 xxx 7 6-1-2022 0 <- per (xxx, 7) missing 7-1-2022
1 xxx 4 7-1-2022 1
2 xxx 7 8-1-2022 0
3 xxx 7 9-1-2022 1
4 yyy 4 10-1-2022 0
5 yyy 7 10-1-2022 0
df['date'] = pd.to_datetime(df['date'], dayfirst=True)
df1 = df.set_index('date').groupby(['id1','id2'])['status'].resample('d').max().reset_index()
df1['status'] = df1['status'].mask(df1['status'].eq(0))
df1['new status'] = df1.groupby(['id1','id2'])['status'].bfill(limit=2).fillna(0).astype(int)
print (df1)
id1 id2 date status new status
0 xxx 4 2022-01-07 1.0 1
1 xxx 7 2022-01-06 NaN 0
2 xxx 7 2022-01-07 NaN 1
3 xxx 7 2022-01-08 NaN 1
4 xxx 7 2022-01-09 1.0 1
5 yyy 4 2022-01-10 NaN 0
6 yyy 7 2022-01-10 NaN 0
df = df.merge(df1.drop('status',axis=1), how='left', on=['id1','id2','date'])
print (df)
id1 id2 date status new status
0 xxx 7 2022-01-06 0 0
1 xxx 4 2022-01-07 1 1
2 xxx 7 2022-01-08 0 1
3 xxx 7 2022-01-09 1 1
4 yyy 4 2022-01-10 0 0
5 yyy 7 2022-01-10 0 0