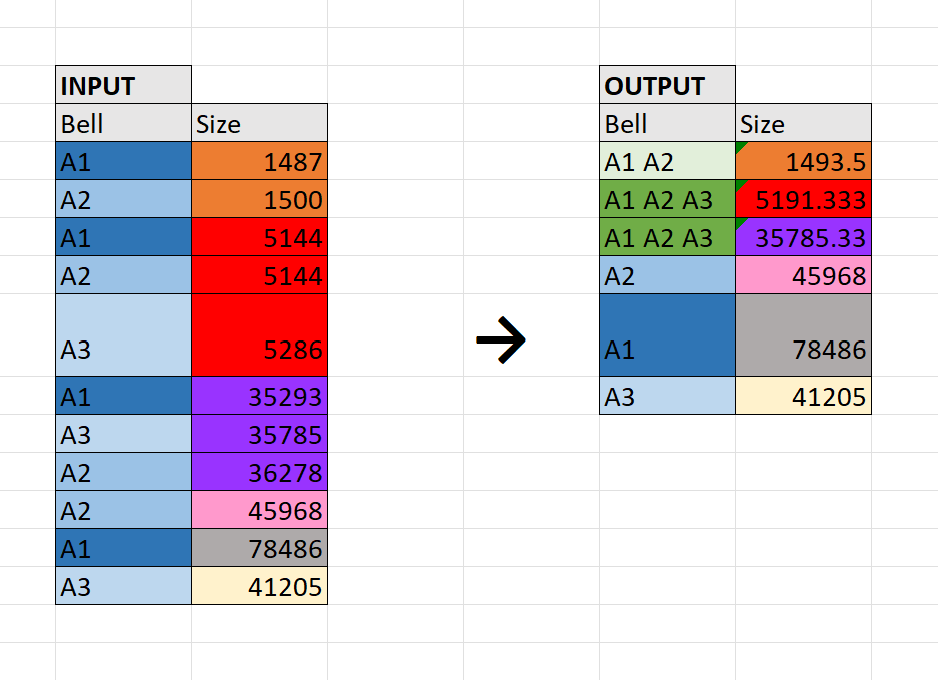
Please, I have a dataframe that is listed in ascending order. My goal is to average similar numbers (numbers that are within 10% of each other in ‘both directions’) and concate their ‘Bell’ name together. For example, the image shows the input and output dataframe. I tried coding it but I stuck on how to progress.
def full_data_compare(self, df_full = pd.DataFrame()):
for k in range(df_full): #current rows
for j in range(df_full): #future rows
if int(df_full['Size'][k]) - int(df_full['Size'][k])*(1/10) <= int(df_full['Size'][j]) <= int(df_full['Size'][k]) int(df_full['Size'][k])*(1/10) & int(df_full['Size'][k]) - int(df_full['Size'][k])*(1/10) <= int(df_full['Size'][j]) <= int(df_full['Size'][k]) int(df_full['Size'][k])*(1/10):
CodePudding user response:
Assuming you really want to check in both directions that the consecutive values are within 10%, you need to compute two Series with pct_change. Then use it to groupby.agg:
#df = df.sort_values(by='Size') for non-consecutive grouping
m1 = df['Size'].pct_change().abs().gt(0.1)
m2 = df['Size'].pct_change(-1).abs().shift().gt(0.1)
out = (df
.groupby((m1|m2).cumsum())
.agg({'Bell': ' '.join, 'Size': 'mean'})
)
NB. If you want to group non-consecutive values, you first need to sort them: sort_values(by='Size')
Output:
Bell Size
Size
0 A1 A2 1493.500000
1 A1 A2 A3 5191.333333
2 A1 A3 A2 35785.333333
3 A2 45968.000000
4 A1 78486.000000
5 A3 41205.000000