I'm trying to scrape some information from a website using Selenium and Python and sometimes there's texts like this HZS stonks remaining... that does not have any name or label that I can get the text by:
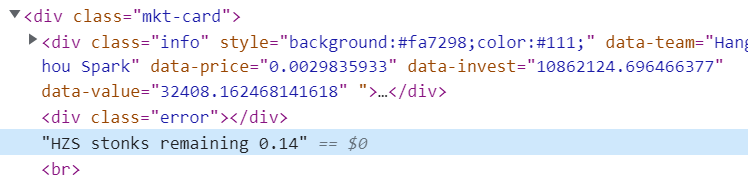
I can get the mkt-card class element easily and I assume that I can somehow get it from the mkt-card element but I can't figure out how to do it.
CodePudding user response:
This is how you can get the text in question:
from bs4 import BeautifulSoup
html = '''
<div ><div>some text</div><div ></div>"HZS stonks remaining 0.14"</div>
'''
soup = BeautifulSoup(html, 'html.parser')
stonks_text = soup.select_one('div.error').next_sibling
print(stonks_text)
This returns "HZS stonks remaining 0.14"
Next time do not post screenshots, but actual text.
CodePudding user response:
As per the HTML:
the desired element is within a text node and is within it's parent element <div >
Solution
To print the text HZS stonks remaining 0.14 you can use either of the following locator strategies:
Using css_selector`:
print(driver.find_element(By.CSS_SELECTOR, "div.mkt-card").text)Using xpath:
print(driver.find_element(By.XPATH, "//div[@class='mkt-card']").text)