Question: Why the myTimeStampCol1 in the following code is returning a null value in the third row, and how can we fix the issue?
from pyspark.sql.functions import *
df=spark.createDataFrame(data = [ ("1","Arpit","2021-07-24 12:01:19.000"),("2","Anand","2019-07-22 13:02:20.000"),("3","Mike","11-16-2021 18:00:08")],
schema=["id","Name","myTimeStampCol"])
df.select(col("myTimeStampCol"),to_timestamp(col("myTimeStampCol"),"yyyy-MM-dd HH:mm:ss.SSSS").alias("myTimeStampCol1")).show()
Output
-------------------- -------------------
|myTimeStampCol | myTimeStampCol1|
-------------------- -------------------
|2021-07-24 12:01:...|2021-07-24 12:01:19|
|2019-07-22 13:02:...|2019-07-22 13:02:20|
| 11-16-2021 18:00:08| null|
Remarks:
- I'm running the code in a python notebook in
Azure Databricks(that is almost the same asDatabricks) - Above example is just a sample to explain the issue. The real code is importing a data file with millions of records. And the file has a column that has the format
MM-dd-yyyy HH:mm:ss(for example11-16-2021 18:00:08) and all the values in that column have exact same formatMM-dd-yyyy HH:mm:ss
CodePudding user response:
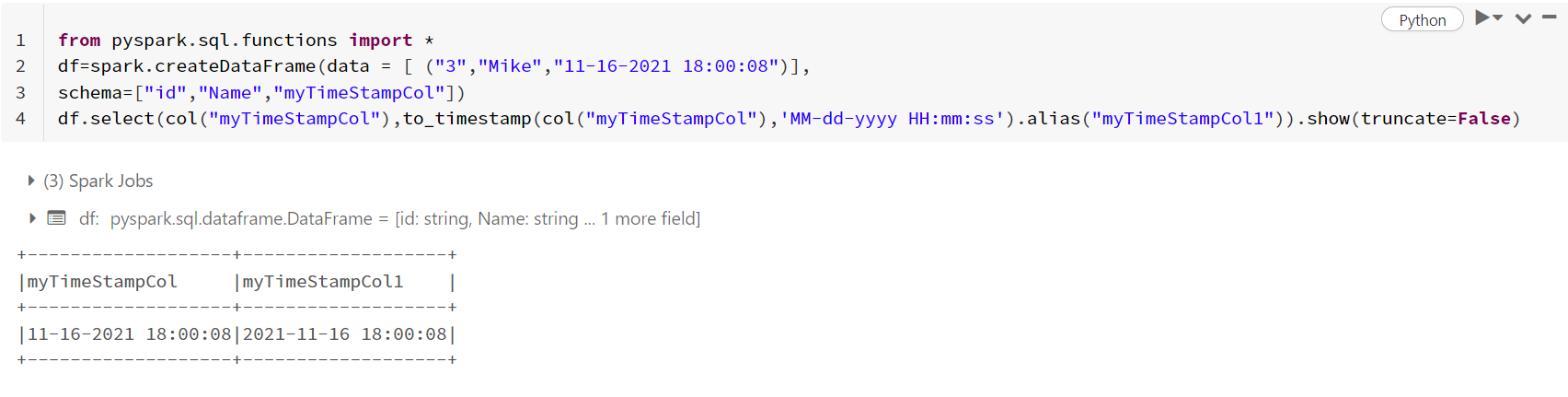
The error occurs because of the difference in formats. Since all the records in this column are in the format MM-dd-yyyy HH:mm:ss, You can modify the code as following.
df.select(col("myTimeStampCol"),to_timestamp(col("myTimeStampCol"),'MM-dd-yyyy HH:mm:ss').alias("myTimeStampCol1")).show(truncate=False)
#only if all the records in this column are 'MM-dd-yyyy HH:mm:ss' format
to_timestamp() column expects either 1 or 2 arguments, a column with these timestamp values and the second is the format of these values. Since all these values are the same format
MM-dd-yyyy HH:mm:ss, you can specify this as the second argument.A sample output for this case is given in the below image:
CodePudding user response:
It seem like your timestamp pattern at index #3 is not aligned with others.
Spark uses the default patterns: yyyy-MM-dd for dates and yyyy-MM-dd HH:mm:ss for timestamps.
Changing the format should solve the problem: 2021-11-16 18:00:08
Edit #1: Alternatively, creating custom transformation function may be a good idea. (Sorry I only found the example with scala). Spark : Parse a Date / Timestamps with different Formats (MM-dd-yyyy HH:mm, MM/dd/yy H:mm ) in same column of a Dataframe