Using the 'mtcars' dataset, how can one split the dataset into clusters using the 'Carb' field and output each grid on a separate pdf document with the Carb value being the name of the pdf document. I am new in R and the solutions I have found enable one to save each cluster on a different page of a pdf document. Have not found one where its possible to save each cluster as a separate document.
CodePudding user response:
You can create pdfs for each part of dataset using approach of parameterized reports in Rmarkdown and not just creating tables, you can create a whole report for each clusters of the dataset.
So to do that, we need to first create a template rmarkdown file containing code for printing data as table where we also need to specify params in yaml of the file.
---
title: "Untitled"
author: "None"
date: '2022-07-26'
output: pdf_document
params:
carb: 1
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
## R Markdown table
```{r, echo=FALSE}
data(mtcars)
df <- mtcars[mtcars$carb %in% params$carb,]
knitr::kable(df, caption = paste("mtcars table for carb", params$carb))
```
Then from a separate R file (r script) or from console run this code which will create six pdfs for each value of carb
lapply(unique(mtcars$carb), function(carb_i) {
rmarkdown::render("tables.Rmd",
params = list(carb = carb_i),
output_file = paste0("table_for_carb",carb_i, ".pdf"))
})
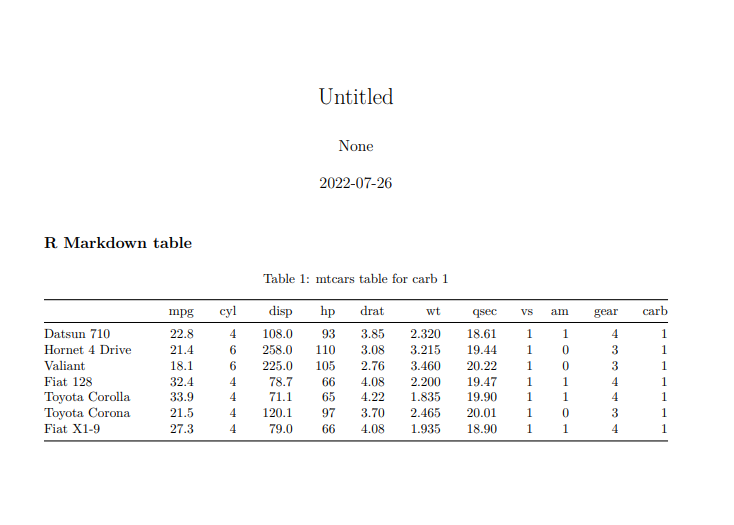
So, for example, table_for_carb1.pdf looks like this
To know more how to create parameterized report with rmarkdown, see here
CodePudding user response:
Here is an option with package gridExtra.
library(gridExtra)
sp <- split(mtcars, mtcars$carb)
lapply(seq_along(sp), \(i) {
carb <- names(sp)[i]
filename <- sprintf("carb%s.pdf", carb)
pdf(filename)
grid.table(sp[[i]])
dev.off()
})
To write the clusters to the same PDF file, one table per page, start by exporting the first table, then, in the lapply loop go to next page and export the next table. The new pages must be between the tables and there must already exist a page (the 1st) before starting a new one for the next table.
And since the filename doesn't depend on the number of carburetors, the code can be simplified and rewritten without the need for seq_along.
library(grid)
library(gridExtra)
sp <- split(mtcars, mtcars$carb)
pdf("carb.pdf")
grid.table(sp[[1]])
lapply(sp[-1], \(x) {
grid.newpage()
grid.table(x)
})
dev.off()