I would like to filter a Spark Dataframe based on a previously filtered out single record. The data looks as follows:
val columns = Seq("language", "users_count", "time_window")
val data = Seq(("Java", "20000", "2021-04-05"),("Java", "20000", "2021-08-05"), ("Python", "100000", "2021-05-05"), ("Scala", "3000", "2021-07-05"), ("Python", "3000", "2021-03-05"))
val rdd = spark.sparkContext.parallelize(data)
val dfFromRDD1 = rdd.toDF(columns: _*)
val dfFromRDD2 = dfFromRDD1.withColumn("time_window", date_format(col("time_window"), "yyyy-MM-dd"))
.orderBy(desc("time_window")) // Note that I sorted the data based on time
Filter record:
val filterRow =
dfFromRDD3.filter(dfFromRDD3("language") === "Python").limit(1)
The expected result should be as in the red box in below picture. Put in words, I would like to only keep those records which came after the most recent Python entry (plus entry containing python).
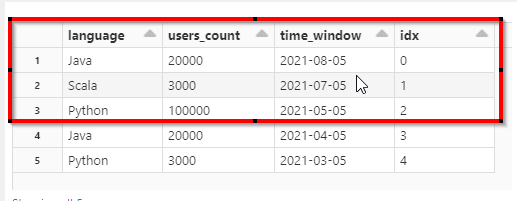
What I tried:
val dfFromRDD3 = dfFromRDD2.withColumn("idx", monotonically_increasing_id())
val result = dfFromRDD3.as("df").join(
filterRow.as("filterRow"),
Seq("idx"),
"left_outer"
).where($"df.idx" <= filterRow("idx").as[Integer])
Explanation: My idea was to create an index column, which can then be used to keep only the desired records.
Note:
- This could probably be done without idx column, but it is nice when joining since no joins on Strings or multiple key columns are needed
- In know filter and where are alias of each other. It just helped to explain the question to distinguish between them.
- Probably I am using the wrong join or something is messed up witht the datatypes?
CodePudding user response:
Suppose we have this table called ds1:
-------- ---------- -----------
|language|user_count|time_window|
-------- ---------- -----------
| Java| 20000| 2021-04-05|
| Scala| 3000| 2021-07-05|
| Java| 20000| 2021-08-05|
| Python| 100000| 2021-05-05|
| Python| 15000| 2021-03-03|
-------- ---------- -----------
Before we move on, we create an id and sort on time_window desc:
ds1 = ds1.withColumn("id", expr("row_number() over (order by time_window desc)"))
Then, we filter the language, we group by id and find the maximum time_window (we group by just to have the value in our table), and we get the id value of the first row (which is the maximum date):
val minId = ds1
.filter(col("language") === "Python")
.groupBy("id").agg(max(col("time_window")))
.rdd.collect()(0)(0)
Finally, we filter ids lower than our found id:
ds1 = ds1.filter(col("id").leq(minId))
Final output:
-------- ---------- ----------- ---
|language|user_count|time_window| id|
-------- ---------- ----------- ---
| Java| 20000| 2021-08-05| 1|
| Scala| 3000| 2021-07-05| 2|
| Python| 100000| 2021-05-05| 3|
-------- ---------- ----------- ---
Hope this helps, good luck!