I am trying to webscrape a site to get addresses for a set of names (part A) along with the longitude and latitudes (part B). I don't know how to do this all together, so I did this in two parts:
# part A
library(tidyverse)
library(rvest)
library(httr)
library(XML)
# Define function to scrape 1 page
get_dental <- function(page_n) {
cat("Scraping page ", page_n, "\n")
page <- paste0("https://www.dentistsearch.ca/search-doctor/",
page_n, "?category=0&services=0&province=55&city=&k=") %>% read_html
tibble(title = page %>%
html_elements(".title a") %>%
html_text2(),
adress = page %>%
html_elements(".marker") %>%
html_text2(),
page = page_n)
}
# Apply function to pages 1:10
df_1 <- map_dfr(1:10, get_dental)
# Check dimensions
dim(df_1)
[1] 90
Here is part B:
# Recognize pattern in websites
part1 = "https://www.dentistsearch.ca/search-doctor/"
part2 = c(0:55)
part3 = "?category=0&services=0&province=55&city=&k="
temp = data.frame(part1, part2, part3)
# Create list of websites
temp$all_websites = paste0(temp$part1, temp$part2, temp$part3)
# Scrape
df_2 <- list()
for (i in 1:10)
{tryCatch({
url_i <-temp$all_websites[i]
page_i <-read_html(url_i)
b_i = page_i %>% html_nodes("head")
listanswer_i <- b_i %>% html_text() %>% strsplit("\\n")
df_2[[i]] <- listanswer_i
print(listanswer_i)
}, error = function(e){})
}
# Extract long/lat from results
lat_long = grep("LatLng", unlist(df_2[]), value = TRUE)
df_2 = data.frame(str_match(lat_long, "LatLng(\\s*(.*?)\\s*);"))
df_2 = df_2 %>% filter(X1 != "LatLngBounds();")
> dim(df_2)
[1] 86 3
We can see that df_1 and df_2 have a different number of rows - but also, there is no common merge key between df_1 and df_2. How can I re-write my code in such a way that I can create a merge key between df_1 and df_2 such that I can merge the common records between these files together?
CodePudding user response:
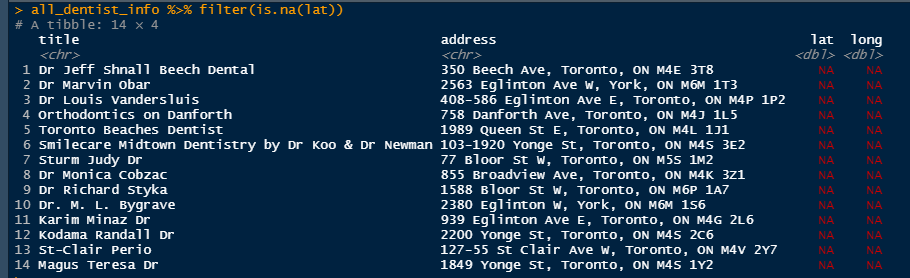
I am not sure multiple requests to the same URIs are needed. There are some lat long values not listed either on the results pages or on the result specific linked webpage e.g.Toronto Beaches Dentist from current page 2 results has no lat long shown on either page 2 or the website specific page. In these cases, you may choose to fill the blanks using another service which returns lat long based on an address.
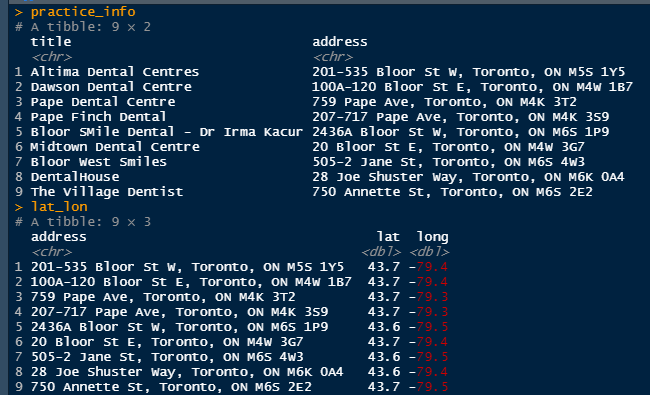
You can re-write your function and alter your regex patterns to produce 2 dataframes which can be joined. The join is a choice of the lesser of 2 evils. With the appropriate regex changes you can simply cbind the 2 dataframes under the assumption ordering is correct, and perhaps with an nrow() check, or use the address column to join the 2 dataframes. I dislike a key which is an address but it does appear to be internally consistent across the result page. I have used a left join to return all rows from the dentist listings i.e. the practice business) names.
library(tidyverse)
library(rvest)
urls <- sprintf("https://www.dentistsearch.ca/search-doctor/%i?category=0&services=0&province=55&city=&k=", 1:10)
pages <- lapply(urls, read_html)
get_dentist_info <- function(page) {
page_text <- page %>% html_text()
address_keys <- page_text %>%
str_match_all('marker_\\d \\.set\\("content", "(.*?)"\\);') %>%
.[[1]] %>%
.[, 2]
lat_long <- page_text %>%
str_match_all("LatLng\\((.*)\\);(?![\\s\\S] myOptions)") %>%
.[[1]] %>%
.[, 2]
lat_lon <- tibble(address = address_keys, lat_long = lat_long) %>%
separate(lat_long, into = c("lat", "long"), sep = ", ") %>%
mutate(lat = as.numeric(lat), long = as.numeric(long))
practice_info <- tibble(
title = page %>% html_elements(".title > a") %>% html_text(trim = T),
address = page %>% html_elements(".marker") %>% html_text()
)
dentist_info <- left_join(practice_info, lat_lon, by = "address")
return(dentist_info)
}
all_dentist_info <- map_dfr(pages, get_dentist_info)
Looking at what is happening with the 2 dataframes:
Looking at missing values: