I've searched quite a bit and can't quite find a question similar to the problem I am trying to solve here: I have a spark dataframe in python, and I need to loop over rows and certain columns in a block to determine if there are non-null values.
The data looks like this (putting it simplistically):

As you can see, I have sorted the data by the ID column. Each ID has potentially multiple rows with different values in the property1-property5 columns. I need to loop over these to be able to check for each unique ID value, if there are any of the property columns (1 to 5) that are not null. I don't care what the values are fortunately - only whether they are null or not. Hence I need the output to be something like this:
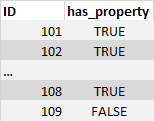
Here we see ID 101, 102 and 108 has some property values that are non-null. However ID 109 only has nulls.
I am not very skilled with Python - I know that I need some soft of a window function (window.partition) and then loop over the columns (for x : x in df.columns). I'd appreciate the help - as I mentioned, I've not been able to find another question that is quite similar to what I am trying to do.
My actual dataset had 167 columns (not all of which I need to consider) and a few million rows. I can easily drop the columns that I don't need to consider, so that I don't need to make a list of the ones that don't need to pass through the loop.
CodePudding user response:
You don't need loops (well, for most cases in spark, this holds true). A when().otherwise() can be used here.
Suppose, you have the input as following
data_sdf = spark.sparkContext.parallelize(data_ls). \
toDF(['id', 'prop1', 'prop2', 'prop3', 'prop4'])
# --- ----- ----- ----- -----
# | id|prop1|prop2|prop3|prop4|
# --- ----- ----- ----- -----
# |101| null| null| null| null|
# |101| 1| null| true| 0|
# |101| 0| 0| null| 10|
# |102| 1| null| true| 0|
# |102| null| 1| null| null|
# |109| null| null| null| null|
# |109| null| null| null| null|
# --- ----- ----- ----- -----
You first check if any of the "prop" containing columns are non-null at a row level. I've used reduce() to avoid writing multiple columns.
data_sdf. \
withColumn('has_prop',
reduce(lambda x, y: x|y, [func.col(k).isNotNull() for k in data_sdf.columns if 'prop' in k])
). \
show()
# --- ----- ----- ----- ----- --------
# | id|prop1|prop2|prop3|prop4|has_prop|
# --- ----- ----- ----- ----- --------
# |101| null| null| null| null| false|
# |101| 1| null| true| 0| true|
# |101| 0| 0| null| 10| true|
# |102| 1| null| true| 0| true|
# |102| null| 1| null| null| true|
# |109| null| null| null| null| false|
# |109| null| null| null| null| false|
# --- ----- ----- ----- ----- --------
# The `reduce` generates the following logic
# Column<'((((prop1 IS NOT NULL) OR (prop2 IS NOT NULL)) OR (prop3 IS NOT NULL)) OR (prop4 IS NOT NULL))'>
The max of has_prop column at an id level would result in the required output. (True > False)
data_sdf. \
withColumn('has_prop',
reduce(lambda x, y: x|y, [func.col(k).isNotNull() for k in data_sdf.columns if 'prop' in k])
). \
groupBy('id'). \
agg(func.max('has_prop').alias('has_prop')). \
show()
# --- --------
# | id|has_prop|
# --- --------
# |101| true|
# |102| true|
# |109| false|
# --- --------
CodePudding user response:
You can achieve this in 2 steps
- Firstly using the inherent property for
max&minto determine if all the rows are null. - Build a consolidated map to mark if all rows are nulls not null
A similar approach & question can be found here
Data Preparation
s = StringIO("""
ID,Company,property1,property2,property3,property4,property5
101,A,,,,,
102,Z,'1','0','0','TRUE',
103,M,'0','0','0','FALSE','FALSE'
104,C,'1','1','0','TRUE','FALSE'
105,F,'0','1',,'TRUE',
""")
df = pd.read_csv(s,delimiter=',').fillna('None') #.reset_index()
sparkDF = sql.createDataFrame(df)
sparkDF = reduce(
lambda df2, x: df2.withColumn(x, F.when(F.col(x) == 'None',F.lit(None)).otherwise(F.col(x))),
[i for i in sparkDF.columns],
sparkDF,
)
sparkDF.show()
--- ------- --------- --------- --------- --------- ---------
| ID|Company|property1|property2|property3|property4|property5|
--- ------- --------- --------- --------- --------- ---------
|101| A| null| null| null| null| null|
|102| Z| '1'| '0'| '0'| 'TRUE'| null|
|103| M| '0'| '0'| '0'| 'FALSE'| 'FALSE'|
|104| C| '1'| '1'| '0'| 'TRUE'| 'FALSE'|
|105| F| '0'| '1'| null| 'TRUE'| null|
--- ------- --------- --------- --------- --------- ---------
Null Row Identification & Marking
ID_null_map = sparkDF.groupBy('Id').agg(*[(
(
F.min(F.col(c)).isNull()
& F.max(F.col(c)).isNull()
)
| ( F.min(F.col(c)) != F.max(F.col(c)) )
).alias(c)
for c in sparkDF.columns if 'property' in c
]
).withColumn('combined_flag',F.array([c for c in ID_null_map.columns if 'property' in c]))\
.withColumn('nulls_free',F.forall('combined_flag', lambda x: x == False))\
ID_null_map.show(truncate=False)
--- --------- --------- --------- --------- --------- ----------------------------------- ----------
|Id |property1|property2|property3|property4|property5|combined_flag |nulls_free|
--- --------- --------- --------- --------- --------- ----------------------------------- ----------
|103|false |false |false |false |false |[false, false, false, false, false]|true |
|104|false |false |false |false |false |[false, false, false, false, false]|true |
|105|false |false |true |false |true |[false, false, true, false, true] |false |
|101|true |true |true |true |true |[true, true, true, true, true] |false |
|102|false |false |false |false |true |[false, false, false, false, true] |false |
--- --------- --------- --------- --------- --------- ----------------------------------- ----------
With the above dataset , you can join it further on Id to get the desired rows