I would like to add a new column between each of the date columns, with the interpolated value using the previous and next value to get a month value.
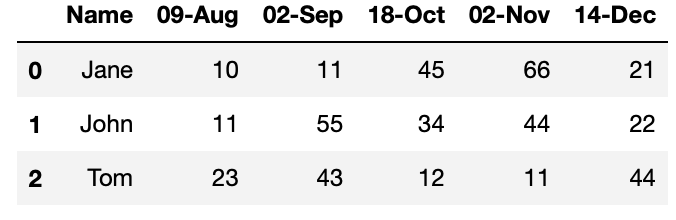
data = [['Jane', 10,11,45,66,21], ['John',11,55,34,44,22],['Tom',23,43,12,11,44]]
df = pd.DataFrame(data, columns = ['Name', '09-Aug', '02-Sep','18-Oct','02-Nov','14-Dec'])
This returns the following:
In between each column after the first one, I would like to add one which contains the month preceding it, and the interpolated value based on the preceding and next column.
So eg:

I tried to first add a column between each one using the following code:
N = len(df.columns) #
for i in range(0,N): #
df.insert(i,'','',allow_duplicates=True)
But this only adds columns to the left of the table, not between each one. Once I had added the columns, I was thinking of writing a function to perform the linear interpolation.
Does anyone have a suggestion on the correct way around to tackle this?
CodePudding user response:
# Make Name your index, and Transpose:
df = df.set_index('Name').T
# Convert index to datetime:
df.index = pd.to_datetime(df.index, format='%d-%b')
# Create new values for each month:
new_index_vals = pd.date_range(df.index.min(), df.index.max(), freq='MS')
# Reindex, including these new values:
df = df.reindex(df.index.union(new_index_vals))
# Apply interpolation, accounting for time:
df = df.interpolate('time') # You can also choose just `linear` here~
# Convert back to original format, formatting month_starts differently:
df.index = np.where(df.index.is_month_start,
df.index.strftime('%B'),
df.index.strftime('%d-%b'))
# Transpose back to original format:
df = df.T.reset_index()
print(df.round(2))
Output:
Name 09-Aug September 02-Sep October 18-Oct November 02-Nov December 14-Dec
0 Jane 10.0 10.96 11.0 32.43 45.0 64.60 66.0 34.93 21.0
1 John 11.0 53.17 55.0 41.76 34.0 43.33 44.0 28.81 22.0
2 Tom 23.0 42.17 43.0 23.46 12.0 11.07 11.0 33.79 44.0
CodePudding user response:
from numpy import nan
import pandas
# Adding a few values
data = [['Jane', 10,11,45,66,21, 45, 70, 60, 80], ['John',11,55,34,44,22, 32, 24, 25, 45],['Tom',23,43,12,11,44, 77, 108, 24, 45]]
df = pd.DataFrame(data, columns = ['Name', '09-Aug', '02-Sep','18-Oct','02-Nov','14-Dec', 'TestDate1', 'TestDate2', 'TestDate3', 'TestDate4'])
df_c = df.drop('Name', axis=1)
for i in range(1, len(df.columns) len(df.columns)-3, 2):
df_c.insert(i, 'Interpolated', pd.Series([nan] * len(df.index)), allow_duplicates=True)
df[['Name']].join(df_c.interpolate(axis=1))

Now you could iterate over all 'Interpolated' columns and use your existing month short form from the left but without the number prefix. The first column would then be called 'Aug'.