I have a table with work shifts (1 row per shift) that include date, start and end time. Main goal: I want to aggregate the number of working hours per hour per store.
This is what my shift table looks like:
| employee_id | store | start_timestamp | end_timestamp |
|---|---|---|---|
| 1 | 1 | 2022-01-01T07:00 | 2022-01-01T11:30 |
| 2 | 1 | 2022-01-01T08:30 | 2022-01-01T12:30 |
| ... | ... | ... | ... |
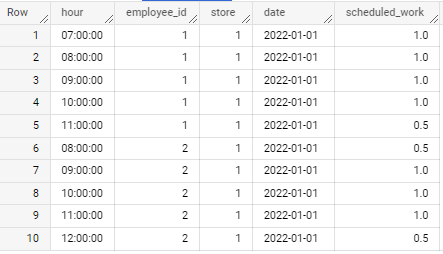
I want to "explode" the information into a table something like this:
| hour | employee_id | store | date | scheduled_work (h) |
|---|---|---|---|---|
| 07:00 | 1 | 1 | 2022-01-01 | 1 |
| 08:00 | 1 | 1 | 2022-01-01 | 1 |
| 09:00 | 1 | 1 | 2022-01-01 | 1 |
| 10:00 | 1 | 1 | 2022-01-01 | 1 |
| 11:00 | 1 | 1 | 2022-01-01 | 0.5 |
| 08:00 | 2 | 1 | 2022-01-01 | 0.5 |
| 09:00 | 2 | 1 | 2022-01-01 | 1 |
| 10:00 | 2 | 1 | 2022-01-01 | 1 |
| 11:00 | 2 | 1 | 2022-01-01 | 1 |
| 12:00 | 2 | 1 | 2022-01-01 | 0.5 |
| ... | ... | ... | ... | ... |
I have tried using a method using cross joins and it consumed a lot of memory and looks like this:
with test as (
select 1 as employee_id, 1 as store_id, timestamp('2022-01-01 07:00:00') as start_timestamp, timestamp('2022-01-01 11:30:00') as end_timestamp union all
select 2 as employee_id, 1 as store_id, timestamp('2022-01-01 08:30:00') as start_timestamp, timestamp('2022-01-01 12:30:00') as end_timestamp
)
, cte as (
select ts
, test.*
, safe_divide(
timestamp_diff(
least(date_add(ts, interval 1 hour), end_timestamp)
, greatest(ts, start_timestamp)
, millisecond
)
, 3600000
) as scheduled_work
from test
cross join unnest(generate_timestamp_array(timestamp('2022-01-01 07:00:00'),
timestamp('2022-01-01 12:30:00'), interval 1 hour)) as ts
order by employee_id, ts)
select * from cte
where scheduled_work >= 0;
It's working but I know this will not be good when the number of shifts starts to add up. Does anyone have another solution that is more efficient?
I'm using BigQuery.
CodePudding user response:
you might want to remove order by inside cte subquery, it'll affect the query performance.
And another similar approach:
WITH test AS (
select 1 as employee_id, 1 as store_id, timestamp('2022-01-01 07:00:00') as start_timestamp, timestamp('2022-01-01 11:30:00') as end_timestamp union all
select 2 as employee_id, 1 as store_id, timestamp('2022-01-01 08:30:00') as start_timestamp, timestamp('2022-01-01 12:30:00') as end_timestamp
),
explodes AS (
SELECT employee_id, store_id, EXTRACT(DATE FROM h) date, TIME_TRUNC(EXTRACT(TIME FROM h), HOUR) hour, 1 AS scheduled_work
FROM test,
UNNEST (GENERATE_TIMESTAMP_ARRAY(
TIMESTAMP_TRUNC(start_timestamp INTERVAL 1 HOUR, HOUR),
TIMESTAMP_TRUNC(end_timestamp - INTERVAL 1 HOUR, HOUR), INTERVAL 1 HOUR
)) h
UNION ALL
SELECT employee_id, store_id, EXTRACT(DATE FROM h), TIME_TRUNC(EXTRACT(TIME FROM h), HOUR),
CASE offset
WHEN 0 THEN 1 - (EXTRACT(MINUTE FROM h) * 60 EXTRACT(SECOND FROM h)) / 3600
WHEN 1 THEN (EXTRACT(MINUTE FROM h) * 60 EXTRACT(SECOND FROM h)) / 3600
END
FROM test, UNNEST([start_timestamp, end_timestamp]) h WITH OFFSET
)
SELECT * FROM explodes WHERE scheduled_work > 0;
CodePudding user response:
Consider below approach
with temp as (
select * replace(
parse_time('%H:%M', start_time) as start_time,
parse_time('%H:%M', end_time) as end_time
)
from your_table
)
select * except(start_time, end_time),
case
when hour = time_trunc(start_time, hour) then (60 - time_diff(start_time, hour, minute)) / 60
when hour = time_trunc(end_time, hour) then time_diff(end_time, hour, minute) / 60
else 1
end as scheduled_work
from (
select time_add(time_trunc(start_time, hour), interval delta hour) as hour,
employee_id, store, date, start_time, end_time
from temp, unnest(generate_array(0,time_diff(end_time, start_time, hour))) delta
)
order by employee_id, hour
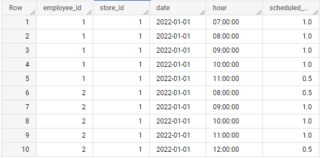
if applied to sample data as in your question

output is