Let's assume that I have data in a df called data_full. From data_full I get
data_filtered <- data_full %>% filter(ua %in% c('a', 'b', 'c'))
Where,
data_filtered <- data.frame(ua = c(rep('a', 3), rep('b', 4), rep('c', 3)),
sp = c(rep('sp1', 3), rep('sp2', 3), rep('sp3', 2), rep('sp4',2)))
Now, I want to select the unique terms that occur in data_filtered$sp without breaking the pipe in the first code (data_filtered <- data_full %>%). Without a pipe I can simply use unique(data_filtered$sp), but how can I keep it in {dplyr} language? distinctworks in my above example, but in my dataset it doesn't since it keeps the uniqueness between ua. I tried to write some replication code with the ''error'' but I couldn't, so I'll print a section of the data (sorry)
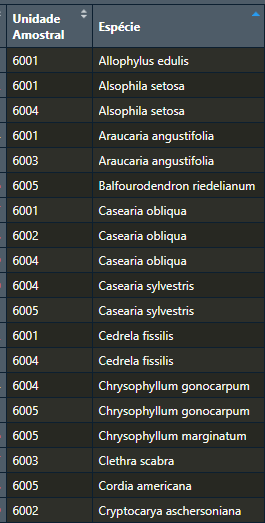
This is after I pipe all the way from data_full into data_filtered. In my example it would be:
data_filtered <- data_full %>%
filter(ua %in% c('a', 'b', 'c')) %>% distinct(sp)
Is this because of "Select only unique/distinct rows from a data frame." on the function description? If so, how can I get the results I want? For example, only one "Alsophila setosa" in my print. I want the final result to be a vector of species names.
EDIT:
As requested:
structure(list(`Unidade Amostral` = c("1000", "1000", "1000",
"1000", "1000", "1000", "1000", "1001", "1001", "1001", "1001",
"1001", "1001", "1001", "1001", "1003", "1003", "1003", "1003",
"1003"), Espécie = c("Aspidosperma australe", "Cupania vernalis",
"Matayba elaeagnoides", "Nectandra megapotamica", "Ocotea puberula",
"Ocotea pulchella", "Parapiptadenia rigida", "Allophylus edulis",
"Araucaria angustifolia", "Hovenia dulcis", "Machaerium paraguariense",
"Matayba elaeagnoides", "Muellera campestris", "Nectandra megapotamica",
"Parapiptadenia rigida", "Clethra scabra", "Ilex brevicuspis",
"Ilex paraguariensis", "Matayba elaeagnoides", "Myrsine coriacea"
), n = c(4, 7, 14, 6, 9, 4, 5, 4, 8, 3, 4, 16, 10, 6, 4, 4, 13,
3, 42, 12)), class = c("grouped_df", "tbl_df", "tbl", "data.frame"
), row.names = c(NA, -20L), groups = structure(list(`Unidade Amostral` = c("1000",
"1001", "1003"), .rows = structure(list(1:7, 8:15, 16:20), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -3L), .drop = TRUE))
CodePudding user response:
Based on the data showed, there is a group attribute, which prevents the distinct from looking over the whole dataset. We need to ungroup first
library(dplyr)
dat %>%
ungroup %>%
distinct(Espécie)
In the case of unique on the extracted the column as a vector, there is no group attribute, as $ or [[ extract will get the whole column whereas within the tidyverse environment, if there is a group attribute, the functions are applied to within each of the group elements