Assuming the dataFrame:
df = pd.DataFrame({
'column_1': ['Apple', 'Apple Apple', 'Apple Apple', 'Peach Peach', 'Banana', 'Banana Banana'],
'column_2': ['Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value']
})
which gives:
column_1 column_2
0 Apple Some value
1 Apple Apple Some value
2 Apple Apple Some value
3 Peach Peach Some value
4 Banana Some value
5 Banana Banana Some value
How do I filter the rows (reassign the df) to only include rows where either the substrings 'Apple' or 'Banana' occur more than once in each string in each cell of column_1?
Note that I'd like to specify the filter to only look for multiple occurrences of 'Apple' & 'Banana' (not programmatically look for all multiple occurrences of any substring, e.g. 'Peach Peach' should not be included).
I.e. the filtering should result in:
column_1 column_2
1 Apple Apple Some value
2 Apple Apple Some value
5 Banana Banana Some value
CodePudding user response:
Check Below answer (kept column Apple_Banana_count for sanity check):
import pandas as pd
import re
df = pd.DataFrame({
'column_1': ['Apple', 'Apple Apple', 'Apple Apple', 'Peach Peach', 'Banana', 'Banana Banana'],
'column_2': ['Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value']
})
df.assign(Apple_Banana_count = df['column_1'].apply(lambda x: len([m.start() for m in re.finditer('Apple|Banana', x)]))).\
query('Apple_Banana_count > 1')
Output:
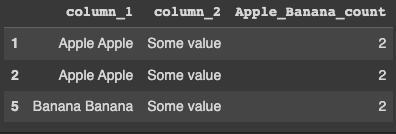
Updated code as per the Op's comment - Leaving unfiltered for Sense Check (You can filter on these columns to get the required result):
import pandas as pd
df = pd.DataFrame({
'column_1': ['Apple', 'Apple Apple', 'Apple Apple', 'Peach Peach', 'Banana', 'Banana Banana', 'Apple Banana','Banana blash blah Apple '],
'column_2': ['Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value']
})
df.assign(Apple_Banana_count = df['column_1'].apply(lambda x: len([m.start() for m in re.finditer('Apple|Banana', x)])),
Apple_and_Banana= df['column_1'].apply(lambda x: len([m.start() for m in re.finditer('(?=.*Apple)(?=.*Banana)', x)]))
)
OutPut:
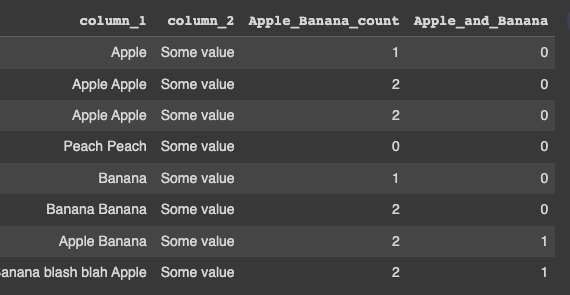
CodePudding user response:
Keeping the rows where 'Apple' or occurs more than once amounts to keeping the rows with at least 2 times 'Apple' and therefore containing 'Apple Apple'. This can be done with
words_to_keep = 'Apple', 'Banana'
words_to_keep = [' '.join([word] * 2) for word in words_to_keep]
# repeat the words 2 times
df = df.loc[df['column_1'].str.contains('|'.join(words_to_keep))]
# keep only the rows containing the repeated words using regex
CodePudding user response:
If the string to match is only Apple and Bananas you can use regex with pandas.Series.str.count.
df[df['column_1'].str.count('Apple|Banana') > 1]
This gives us the expected output
column_1 column_2
1 Apple Apple Some value
2 Apple Apple Some value
5 Banana Banana Some value
EDIT:
As @ouroboros1, suggested the above won't work in case OP has Apple Banana in the row.
Here is the case where I have tried to cover such cases.
df = pd.DataFrame({
'column_1': ['Apple Banana','Apple', 'Apple Apple', 'Apple Apple', 'Peach Peach', 'Banana', 'Banana Banana', 'Apple Banana Apple'],
'column_2': ['Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value', 'Some value']
})
column_1 column_2
0 Apple Banana Some value
1 Apple Some value
2 Apple Apple Some value
3 Apple Apple Some value
4 Peach Peach Some value
5 Banana Some value
6 Banana Banana Some value
7 Apple Banana Apple Some value
We can use extractall to get our pattern group in multiple columns then we apply count to get all not nan values count then we use reindex to get the dataframe containing false value for those rows that did not have a match and filled those value with False. We then select only those values containing atleast one True value. Then we filter our original dataframe with True values in the index.
df[(df['column_1'].str.extractall('(Apple)|(Banana)').groupby(level=0).agg('count')>1).reindex(df.index, fill_value=False).any(axis=1)]
This gives is the expected output
column_1 column_2
2 Apple Apple Some value
3 Apple Apple Some value
6 Banana Banana Some value
7 Apple Banana Apple Some value
CodePudding user response:
This appears to work for my purposes (thanks to @Himanshuman for pointing in this direction):
import re
df = df[
(df['column_1'].str.count(r'apple', re.I) > 1) | \
(df['column_1'].str.count(r'banana', re.I) > 1)
]
It uses the bitwise OR operator (|) between the conditions [with \ as line break character]
and will give the desired result):
column_1 column_2
1 Apple Apple Some value
2 Apple Apple Some value
5 Banana Banana Some value
6 Apple is Apple Some value
7 Banana is not Apple but is Banana Some value