So here is an example of what my dataset would look like below. It would probably be in the form of a pandas dataframe, but can be anything that is accessible in python.
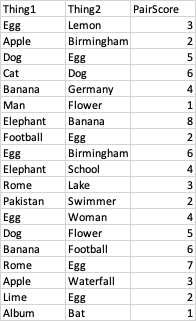
Let's say for example my 'Thing' of interest was 'Egg'. I would like to search through all of the rows of the Thing1 and Thing2 columns for whenever 'Egg' appears in one of these columns, and if the value in the PairScore column in this same same row is below 3, then I would like to return the 'Thing' that occupies the other column.
So for this example, the first 'Thing' that would be returned would be 'Football' from row 9. And then would want to store all of the 'Things' that get returned in something like a list or maybe a new dataframe.
I hope this makes sense, if I need to expand on anything please let me know! :)
CodePudding user response:
prevs = []
data = df[(~df[['Thing1', 'Thing2']].isin(prevs)).all(1)) & (df[['Thing1', 'Thing2']] == 'Egg').any(1) & (df['PairScore'] < 3)]
df = pd.Series(data.values.flatten())
prevs = df.loc[df != "Egg"].tolist() "Egg"
CodePudding user response:
For two columns, I'd just use a combination of boolean indexes:
data = {'Thing1': ['Egg', 'Apple', 'Dog', 'Cat', 'Banana', 'Man', 'Elephant', 'Football', 'Egg', 'Elephant',
'Rome', 'Pakistan', 'Egg', 'Dog', 'Banana', 'Rome', 'Apple', 'Lime', 'Album'],
'Thing2': ['Lemon', 'Birmingham', 'Egg', 'Dog', 'Germany', 'Flower', 'Banana', 'Egg', 'Birmingham',
'School', 'Lake', 'Swimmer', 'Woman', 'Flower', 'Football', 'Egg', 'Waterfall', 'Egg', 'Bat'],
'PairScore': [3, 2, 5, 6, 4, 1, 8, 2, 6, 4, 3, 2, 4, 5, 6, 7, 3, 2, 1]}
df = pd.DataFrame(data)
>>> df.head()
Thing1 Thing2 PairScore
0 Egg Lemon 3
1 Apple Birmingham 2
2 Dog Egg 5
3 Cat Dog 6
4 Banana Germany 4
Selecting as per your criteria
m = df.Thing1.eq("Egg") | df.Thing2.eq("Egg")
# or even m = df.filter(like="Thing").eq("Egg").any(axis=1)
df2 = df[m & df.PairScore.lt(3)]
Result:
Thing1 Thing2 PairScore
7 Football Egg 2
17 Lime Egg 2
From there, one option to proceed is to .stack() the Thing columns into a single column, e.g., do df3[~df3.eq("Egg")] to get rid of rows containing "Egg".
>>> df3 = df2.filter(like="Thing").stack()
>>> df3
7 Thing1 Football
Thing2 Egg
17 Thing1 Lime
Thing2 Egg
dtype: object
>>> df3[~df3.eq("Egg")]
7 Thing1 Football
17 Thing1 Lime
dtype: object
In order to do subsequent analyses on df, excluding the rows from df2 above, you can proceed with
>>> df4 = pd.concat([df, df2]).drop_duplicates(keep=False)
df4 now contains everything from df except of the previous matches:
>>> df4.tail()
Thing1 Thing2 PairScore
13 Dog Flower 5
14 Banana Football 6
15 Rome Egg 7
16 Apple Waterfall 3
18 Album Bat 1 # 17 is gone