I have been banging my head against a wall for a while now trying to figure out this seemingly easy data manipulation task in Pandas, however I have had no success figuring out how to do it or googling a sufficient answer :(
All I want to do is take the table on the left of the snip below (will be a pandas dataframe) and convert it into the table on the right (to become another pandas dataframe).
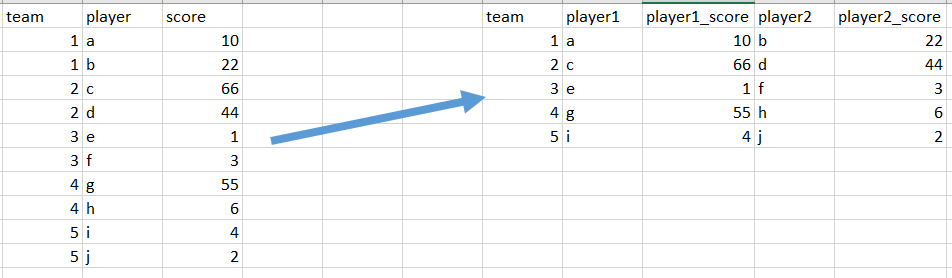
Code for creating the initial dataframe:
import pandas as pd
test_data = pd.DataFrame(
{
'team': [1,1,2,2,3,3,4,4,5,5] ,
'player': ['a','b','c','d','e','f','g','h','i','j'] ,
'score': [10,22,66,44,1,3,55,6,4,2]
}
)
Thank you for your help in advance!
CodePudding user response:
try this,
test_data.groupby('team').agg({'player':['first', 'last'], 'score': ['first', 'last']})
O/P:
player_first player_last score_first score_last
team
1 a b 10 22
2 c d 66 44
3 e f 1 3
4 g h 55 6
5 i j 4 2
Complete solution:
test_data = test_data.groupby('team').agg({'player':['first', 'last'], 'score': ['first', 'last']})
test_data.columns = ['_'.join(x) for x in test_data.columns]
test_data = test_data.reset_index()
test_data = test_data[['team', 'player_first', 'score_first', 'player_last', 'score_last']]
O/P:
team player_first score_first player_last score_last
0 1 a 10 b 22
1 2 c 66 d 44
2 3 e 1 f 3
3 4 g 55 h 6
4 5 i 4 j 2
- What you need is groupby and aggregation ops of first and last
- set column names
- reset index and re order columns
CodePudding user response:
Assuming your dataframe is sorted by team and you know there's exactly 2 entries for each team, you can use:
player_1_data = test_data.iloc[::2, :]
player_2_data = test_data.iloc[1::2, :]
player_1_data.set_index("team")
.add_suffix("1")
.join(player_2_data.set_index("team").add_suffix("2"))
.reset_index()
.rename({"score1": "player1_score", "score2": "player2_score"}, axis=1)
Here, we just pick up alternating rows and join them together to give:
team player1 player1_score player2 player2_score
0 1 a 10 b 22
1 2 c 66 d 44
2 3 e 1 f 3
3 4 g 55 h 6
4 5 i 4 j 2
CodePudding user response:
You can do in this way:
import pandas as pd
df = pd.DataFrame(
{
'team': [1,1,2,2,3,3,4,4,5,5] ,
'player': ['a','b','c','d','e','f','g','h','i','j'] ,
'score': [10,22,66,44,1,3,55,6,4,2]
}
)
grouped_df = df.groupby('team').agg({ 'player': ['first', 'last'], 'score': ['first', 'last']})
grouped_df.columns = [ 'player_first', 'score_first', 'player_last', 'score_last']
print(grouped_df)