Basic concept I know:
find_element = find single elements. We can use .text or get.attribute('href') to make the element can be readable. Since find_elements is a list, we can't use .textor get.attribute('href') otherwise it shows no attribute.
To scrape information to be readable from find_elements, we can use for loop function:
vegetables_search = driver.find_elements(By.CLASS_NAME, "product-brief-wrapper")
for i in vegetables_search:
print(i.text)
Here is my problem, when I use find_element, it shows the same result. I searched the problem on the internet and the answer said that it's because using find_element would just show a single result only. Here is my code which hopes to grab different urls.
links.append(driver.find_element(By.XPATH, ".//a[@rel='noopener']").get_attribute('href'))
But I don't know how to combine the results into pandas. If I print these codes, links variable prints the same url on the csv file...
vegetables_search = driver.find_elements(By.CLASS_NAME, "product-brief-wrapper")
Product_name =[]
links = []
for search in vegetables_search:
Product_name.append(search.find_element(By.TAG_NAME, "h4").text)
links.append(driver.find_element(By.XPATH, ".//a[@rel='noopener']").get_attribute('href'))
#use panda modules to export the information
df = pd.DataFrame({'Product': Product_name,'Link': links})
df.to_csv('name.csv', index=False)
print(df)
Certainly, if I use loop function particularly, it shows different links.(That's mean my Xpath is correct(!?))
product_link = (driver.find_elements(By.XPATH, "//a[@rel='noopener']"))
for i in product_link:
print(i.get_attribute('href'))
My questions:
- Besides using for loop function, how to make
find_elementsbecomes readable? Just likefind_element(By.attribute, 'content').text - How to go further step for my code? I cannot print out different urls. Thanks so much. ORZ
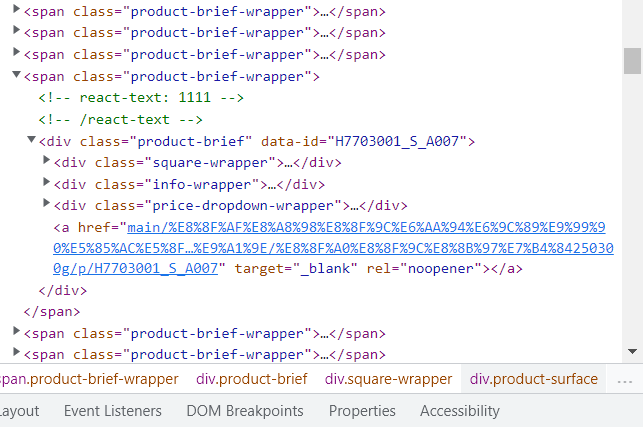
This is the html code which's inspected from the website:
CodePudding user response:
This line:
links.append(driver.find_element(By.XPATH, ".//a[@rel='noopener']").get_attribute('href'))
should be changed to be
links.append(search.find_element(By.XPATH, ".//a[@rel='noopener']").get_attribute('href'))
driver.find_element(By.XPATH, ".//a[@rel='noopener']").get_attribute('href') will always search for the first element on the DOM matching .//a[@rel='noopener'] XPath locator while you want to find the match inside another element.
To do so you need to change WebDriver driver object with WebElement search object you want to search inside, as shown above.