I'm looking for a way to perform a full join on 2 tibbles, by a column with unique indices, in a way that would preserve the original column names and merge (non-identical) values into a vector or list. The tibbles have the same column names.
Example input tibbles
> a
# A tibble: 3 × 3
id name location
<dbl> <chr> <chr>
1 1 Caspar NL
2 2 Monica USA
3 3 Martin DE
> b
# A tibble: 3 × 3
id name location
<dbl> <chr> <chr>
1 1 Caspar WWW
2 2 Monique USA
3 4 Francis FR
Desired output
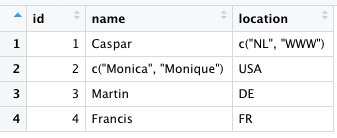 or:
or: 
The ability to handle more than just 2 tibbles at the same time would be ideal.
All I know is dyplr's full_join(), which doesn't give me the desired result:
> dplyr::full_join(a,b, by='id')
# A tibble: 4 × 5
id name.x location.x name.y location.y
<dbl> <chr> <chr> <chr> <chr>
1 1 Caspar NL Caspar WWW
2 2 Monica USA Monique USA
3 3 Martin DE NA NA
4 4 NA NA Francis FR
Reprex
a <- tibble::tribble(~id, ~name, ~location, 1, 'Caspar', 'NL', 2, 'Monica', 'USA', 3, 'Martin', 'DE')
b <- tibble::tribble(~id, ~name, ~location, 1, 'Caspar', 'WWW', 2, 'Monique', 'USA', 4, 'Francis', 'FR')
CodePudding user response:
It may be better with binding the rows first and then do a group by summarise
library(dplyr)
bind_rows(a, b) %>%
group_by(id) %>%
summarise(across(c('name', 'location'), list), .groups = 'drop')
-output
# A tibble: 4 × 3
id name location
<dbl> <list> <list>
1 1 <chr [2]> <chr [2]>
2 2 <chr [2]> <chr [2]>
3 3 <chr [1]> <chr [1]>
4 4 <chr [1]> <chr [1]>