I'm trying to sum previous rows of data based on a filter of name_ex and a specified number of rounds. More specifically:
Goal: To sum the previous 3 rows of stat1 and stat2 respectively. These sums should only occur if the name_ex criteria is met. ie only sum stat1 and stat2 from Steve's rows (sum Steve's data, Bill's data, but avoid using Steve's data in Bill's.).
Additional Goal: Preferably, instead of summing just the last 3 rows, I would like to sum the rows of stat1 and stat2 based off a filter of rounds. Ie sum all the rounds up until rounds equals between 10 and 12. I'm not sure if this is achievable within a dplyr function or if I need to write a function to achieve it.
Work: I used the group_by function to get the data in it's desired form so I can use zoo to sum the last 3 rows of data.
Issues: My function solely calls the last 3 rows of data regardless of criteria. This is a problem because I'm not able to separate the data by each person's name (ie Bill pulls from Steve's). Additionally, I'm looking for a simplistic filter that pulls rows where name_ex criteria is met and rounds are between 10 and 12 (cumulatively).
#Load packages
library(dplyr)
library(tidyverse)
library(zoo)
#Reprex
name_ex <- c("steve", "steve","steve", "steve","steve","steve", "steve", "bill", "bill", "bill", "bill", "bill", "bill", "bill", "bill", "john","john","john", "john","john","john", "john")
rounds <- c(4, 4, 4, 2, 4, 4, 4, 4, 4, 4, 2, 4, 2, 4, 2, 4, 4, 4, 4, 4, 4, 2)
t_id <- c(1, 2, 3, 4, 1, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 4, 1, 2, 3, 4)
year <- c(2019, 2019,2019, 2019, 2020, 2020, 2020, 2019, 2019, 2019, 2019, 2020, 2020, 2020, 2020, 2019, 2019, 2019, 2020, 2020, 2020, 2020)
stat1 <- c(3.2, 3.4, -1.4, 2.1, 1.3, -1.7, -1.7, 1.1, 2.0, 1.3, .7, 1.5, 1.2, 2.5, 3.6, -1.1, 0.4, -1.2, -1.1, 1.6, 1.3, -2.7)
stat2 <- c(1.7, 1.2, 1.3, -.4, 1.1, 2.1, -2.1, .6, 1.1, 3.4, -1.1, -1.7, -1.3, 1.1, 2.4, 1.3, 2.6, .6, 1.3, .7, 2.3, -2.4)
event_n <- c(1, 2, 3, 4, 5, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 4, 5, 6, 7, 8)
test_df <- do.call(rbind, Map(data.frame, name_ex =name_ex, year = year, t_id = t_id, event_n = event_n, rounds =rounds, stat1 = stat1, stat2 = stat2))
#Sum the previous 3 columns of data for stat1 and stat2
test_df2 <- test_df %>%
group_by(name_ex, t_id, year)
test_df2$stat1_sum <- lag(rollsumr(test_df2$stat1, k = 3, fill = NA))
test_df2$stat2_sum <- lag(rollsumr(test_df2$stat2, k = 3, fill = NA))
test_df2
#bad attempt at filtering for name
#test_df2$stat1_sum <- lag(rollsumr(test_df2$stat1[name_ex == name_ex], k = 3, fill = NA))
CodePudding user response:
I think your first question can easily be answered using only dplyr if you first convert your data to long format. (This also makes your data tidy.)
longDF <- test_df %>%
pivot_longer(
starts_with("stat"),
names_to="Statistic",
values_to="Value"
) %>%
arrange(Statistic, name_ex, year) %>%
group_by(name_ex, Statistic) %>%
mutate(
ValueLag1=lag(Value),
ValueLag2=lag(Value, 2)
)
longDF
# A tibble: 44 × 9
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value ValueLag1 ValueLag2
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA NA
2 bill 2019 2 2 4 stat1 2 1.1 NA
3 bill 2019 3 3 4 stat1 1.3 2 1.1
4 bill 2019 4 4 2 stat1 0.7 1.3 2
5 bill 2020 1 5 4 stat1 1.5 0.7 1.3
6 bill 2020 2 6 2 stat1 1.2 1.5 0.7
7 bill 2020 3 7 4 stat1 2.5 1.2 1.5
8 bill 2020 4 8 2 stat1 3.6 2.5 1.2
9 john 2019 1 1 4 stat1 -1.1 NA NA
10 john 2019 2 2 4 stat1 0.4 -1.1 NA
# … with 34 more rows
The use of group_by() prevents one person's stats carrying over to the next person. You can clearly see the effect in the output above.
Calculating the "sum of the last three" is now also simple:
longDF %>%
mutate(SumOfLastThree=Value ValueLag1 ValueLag2) %>%
select(-ValueLag1, -ValueLag2)
# A tibble: 44 × 8
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value SumOfLastThree
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA
2 bill 2019 2 2 4 stat1 2 NA
3 bill 2019 3 3 4 stat1 1.3 4.4
4 bill 2019 4 4 2 stat1 0.7 4
5 bill 2020 1 5 4 stat1 1.5 3.5
6 bill 2020 2 6 2 stat1 1.2 3.4
7 bill 2020 3 7 4 stat1 2.5 5.2
8 bill 2020 4 8 2 stat1 3.6 7.3
9 john 2019 1 1 4 stat1 -1.1 NA
10 john 2019 2 2 4 stat1 0.4 NA
# … with 34 more rows
Does this give your expected output?
Consider
longDF %>%
mutate(
CumulativeRounds=ifelse(
row_number() == 1,
rounds,
rounds lag(rounds)
)
)
# A tibble: 44 × 10
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value ValueLag1 ValueLag2 CumulativeRounds
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA NA 4
2 bill 2019 2 2 4 stat1 2 1.1 NA 8
3 bill 2019 3 3 4 stat1 1.3 2 1.1 8
4 bill 2019 4 4 2 stat1 0.7 1.3 2 6
5 bill 2020 1 5 4 stat1 1.5 0.7 1.3 6
6 bill 2020 2 6 2 stat1 1.2 1.5 0.7 6
7 bill 2020 3 7 4 stat1 2.5 1.2 1.5 6
8 bill 2020 4 8 2 stat1 3.6 2.5 1.2 6
9 john 2019 1 1 4 stat1 -1.1 NA NA 4
10 john 2019 2 2 4 stat1 0.4 -1.1 NA 8
# … with 34 more rows
So
longDF %>%
select(-ValueLag1, -ValueLag2) %>%
mutate(
CumulativeRounds=ifelse(
row_number() == 1,
rounds,
rounds lag(rounds)
)
) %>%
filter(CumulativeRounds >= 8 & CumulativeRounds <= 10)
# A tibble: 22 × 8
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value CumulativeRounds
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 bill 2019 2 2 4 stat1 2 8
2 bill 2019 3 3 4 stat1 1.3 8
3 john 2019 2 2 4 stat1 0.4 8
4 john 2019 4 4 4 stat1 -1.2 8
5 john 2020 1 5 4 stat1 -1.1 8
6 john 2020 2 6 4 stat1 1.6 8
7 john 2020 3 7 4 stat1 1.3 8
8 steve 2019 2 2 4 stat1 3.4 8
9 steve 2019 3 3 4 stat1 -1.4 8
10 steve 2020 3 7 4 stat1 -1.7 8
Is, I believe, what you want.
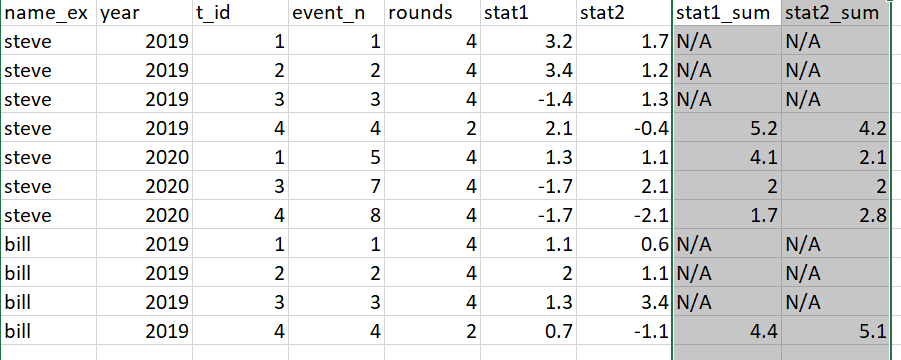
Edit
OP has now posted an image clarifying what they mean by "last three rows". My suggested solutiuon for the first part of their problem can be easily adapted to produce the required results.
test_df %>%
pivot_longer(
starts_with("stat"),
names_to="Statistic",
values_to="Value"
) %>%
arrange(Statistic, name_ex, year, t_id) %>%
group_by(name_ex, Statistic) %>%
mutate(
ValueLag1=lag(Value),
ValueLag2=lag(Value, 2),
ValueLag3=lag(Value, 3),
SumOfPreviousThree=ValueLag1 ValueLag2 ValueLag3
) %>%
select(-ValueLag1, -ValueLag2, -ValueLag3)
# A tibble: 44 × 8
# Groups: name_ex, Statistic [6]
name_ex year t_id event_n rounds Statistic Value SumOfPreviousThree
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 bill 2019 1 1 4 stat1 1.1 NA
2 bill 2019 2 2 4 stat1 2 NA
3 bill 2019 3 3 4 stat1 1.3 NA
4 bill 2019 4 4 2 stat1 0.7 4.4
5 bill 2020 1 5 4 stat1 1.5 4
6 bill 2020 2 6 2 stat1 1.2 3.5
7 bill 2020 3 7 4 stat1 2.5 3.4
8 bill 2020 4 8 2 stat1 3.6 5.2
9 john 2019 1 1 4 stat1 -1.1 NA
10 john 2019 2 2 4 stat1 0.4 NA
# … with 34 more rows
To return to OP's untidy format, add the following to the end of the pipe:
%>%
pivot_wider(
values_from=c(Value, SumOfPreviousThree),
names_from=Statistic
)