I have a dataframe where names of the columns are concatentated from names of the previous columns - like so :

And the rows have 1 or 0 values. What I wish to do is to check which subtag each of the 1s belongs to and change the value of the parent tags for that subtag to 1s also (if it isnt already so). As follows : 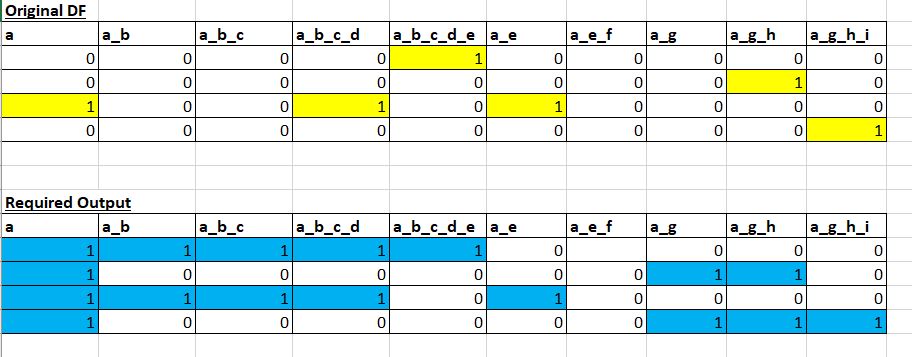
I hope I have been able to make the problem statement clear.
Thanks in advance for any help.
print (df)
a a_b a_b_c a_b_c_d a_b_c_d_e a_e a_e_f a_g a_g_h a_g_h_i
0 0 0 0 0 1 0 0 0 0 0
1 0 0 0 0 0 0 0 0 1 0
2 1 0 0 1 0 1 0 0 0 0
3 0 0 0 0 0 0 0 0 0 1
CodePudding user response:
Create groups for test if not exist previous value in columns name, then replace 0 to misisng values and per groups back filling missing values, last replace missing values not replaced to 0:
s = df.columns.to_series()
groups = np.cumsum([not b in a for a, b in zip(s, s.shift(fill_value='missing'))])
df1 = df.mask(df.eq(0)).groupby(groups, axis=1).bfill().fillna(0, downcast='infer')
print (df1)
a a_b a_b_c a_b_c_d a_b_c_d_e a_e a_e_f a_g a_g_h a_g_h_i
0 1 1 1 1 1 0 0 0 0 0
1 0 0 0 0 0 0 0 1 1 0
2 1 1 1 1 0 1 0 0 0 0
3 0 0 0 0 0 0 0 1 1 1
CodePudding user response:
With the help of numpy you can use np.where() to find the coordinates where the value is 1. Then you can find the parent tags that need to be changed by comparing the column names. Once you have the coordinates of the column names you want to change, you can replace the values.
coordinates = [(x, df.columns[y]) for x, y in zip(*np.where(df.values == 1))]
new_subtags = [(items[0], col_name) for items in coordinates for col_name in df.columns if col_name in items[1]]
for item in new_subtags:
df.at[item[0], item[1]] = 1
This should result in your desired output:
a a_b a_b_c a_b_c_d a_b_c_d_e a_e a_e_f a_g a_g_h a_g_h_i
0 1 1 1 1 1 0 0 0 0 0
1 1 0 0 0 0 0 0 1 1 0
2 1 1 1 1 0 1 0 0 0 0
3 1 0 0 0 0 0 0 1 1 1