Having a data frame as below:
data = {'number':[4,3,3,3,3,3,3,3,3,3,4,5],'name':['L6','L6','L6','L6','L6','L8','L8','L8','L9','L9','L8','L9'],
'product1':['B','C','A','A','A','A','B','B','D','D','D','E'],
'product2':['D','A','B','Z','C','G','G','T','E','W','T','Q']}
df = pd.DataFrame(data)
df
Needs to replace all the rows or reindex the rows at the begining of the dataframe based on a list.
lst = [(3,'L6','A'),(3,'L8','B'),(3,'L9','D')]
The below figure shows the expected output:
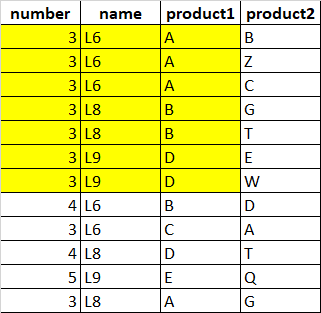
CodePudding user response:
Use pd.MultiIndex and get_indexer_for to get the indexes for the values in my_list.
Then find remaining indexes by using np.setdiff1d with np.arange(len(df)) and first indexes found
Then use np.concatenate to combine those to get the desired order of indexes
Then reindex df with new order.
my_list = [(3,'L6','A'),(3,'L8','B'),(3,'L9',D)] #Don't use 'list' for name
mi = pd.MultiIndex.from_arrays([df['number'], df['name'], df['product1']])
first_rows_indexes = mi.get_indexer_for(my_list)
remaining_indexes = np.setdiff1d(np.arange(len(df)), first_rows_indexes)
df = df.reindex(np.concatenate([first_rows_indexes, remaining_indexes]))
print(df):
number name product1 product2
2 3 L6 A B
3 3 L6 A Z
4 3 L6 A C
6 3 L8 B G
7 3 L8 B T
8 3 L9 D E
9 3 L9 D W
0 4 L6 B D
1 3 L6 C A
5 3 L8 A G
10 4 L8 D T
11 5 L9 E Q
CodePudding user response:
Create a dataframe from the list of tuples, then outer merge with given dataframe to automatically sort based on the order of keys in lst
order = pd.DataFrame(lst, columns=['number', 'name', 'product1'])
order.merge(df, how='outer', sort=False)
number name product1 product2
0 3 L6 A B
1 3 L6 A Z
2 3 L6 A C
3 3 L8 B G
4 3 L8 B T
5 3 L9 D E
6 3 L9 D W
7 4 L6 B D
8 3 L6 C A
9 3 L8 A G
10 4 L8 D T
11 5 L9 E Q