df
ColA ColB ColC CodD ColF
1. 2. 3. 1. T
2. 2. 3. 1. T
3. 2. 3. 1. F
4. 2. 3. 1. F
5. 2. 3. 1. T
6. 2. 3. 2. T
7. 2. 3. 2. T
8. 2. 3. 2. T
9. 2. 3. 2. F
10. 2. 3. 2. F
11. 2. 3. 2. F
12. 2. 3. 2. T
13. 2. 3. 2. T
desired output
ColB ColC CodD ColF grp grpcount
2. 3. 1. T. 1. 2
2. 3. 1. F. 2. 2
2. 3. 1. T. 3. 1
2. 3. 2. T. 1. 3
2. 3. 2. F. 2. 3
2. 3. 2. T. 3. 2
I tried
df_2 = df.sort_values(['ColA'],ascending=True).groupby(['ColB','ColC','ColD','ColF'])['ColA'].count().reset_index(name='grpcount')
the T and F in each group returns just two groups but I want the pattern of each grouping. any help. So even though we have T , F in a group. the sequence should be counted and maintained.
recreating the data :
Data = {
'ColA':['1','2','3','4','5','6','7','8','9','10','11','12','13'],
'ColB':['2','2','2','2','2','2','2','2','2','2','2','2','2'],
'ColC':['3','3','3','3','3','3','3','3','3','3','3','3','3'],
'ColD':['1','1','1','1','1','2','2','2','2','2','2','2','2'],
'ColF':['T','T','F','F','T','T','T','T','F','F','F','T','T']}
df = pd.DataFrame(Data,columns=['ColA','ColB','ColC','ColD','ColF'])
print(df)
CodePudding user response:
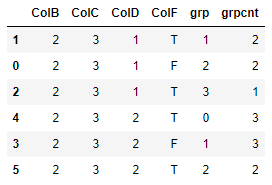
Does this work for you?
# shift ColF and flag changes
df["Shift"] = df.ColF != df.ColF.shift()
# cumsum the bools in Shift to flag when the sequence changes (i.e. make groups)
df["grp"] = df.groupby([
"ColB",
"ColC",
"ColD",
])["Shift"].cumsum()
# groupby the cols and count!
out = df.groupby([
"ColB",
"ColC",
"ColD",
"ColF",
"grp"
], as_index=False).ColA.count().rename(columns={
"ColA": "grpcnt"
})
# sort to match desired output
out.sort_values([
"ColB",
"ColC",
"ColD",
"grp",
"grpcnt",
"ColF",
], inplace=True)
out
Reference: https://stackoverflow.com/a/53542712/6509519