I want to make a basic split (see image below) with Python/Pandas.
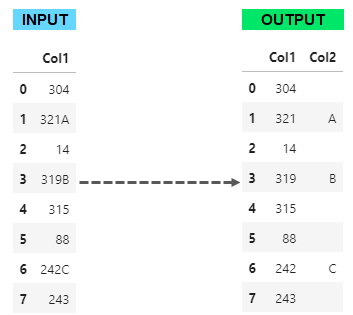
For people who use Excel/PowerQuery, there is a nice function that allow them to do that, Splitter.SplitTextByCharacterTransition.
I tried to make an equivalent in Python using itertools but unfortunately I get a copy of the column "Col1":
import pandas as pd
import itertools
df = pd.DataFrame({'Col1': ['304', '321A', '14', '319B', '315', '88', '242C', '243']})
df['Col2'] = [''.join(a) for b, a in itertools.groupby(df['Col1'])]
>>> df
Col1 Col2
0 304 304
1 321A 321A
2 14 14
3 319B 319B
4 315 315
5 88 88
6 242C 242C
7 243 243
Do you have any suggestions/propositions to fix that, please ?
CodePudding user response:
Let us do extract
df['Col1'].str.extract(r'^(\d )(.*)').fillna('')
0 1
0 304
1 321 A
2 14
3 319 B
4 315
5 88
6 242 C
7 243
CodePudding user response:
Let's try .str.extractall to extract both the number and character then get the first non value in group
out = df.join(df.pop('Col1')
.str.extractall('(\d )|([a-zA-Z] )')
.groupby(level=0).first()
.fillna('')
.set_axis(['Col1', 'Col2'], axis=1))
print(out)
Col1 Col2
0 304
1 321 A
2 14
3 319 B
4 315
5 88
6 242 C
7 243
CodePudding user response:
try Regular Expressions for work with text
Code that worked for me:
import pandas as pd
import itertools
import re
df = pd.DataFrame({'Col1': ['304', '321A', '14', '319B', '315', '88', '242C', '243']})
df['Col2'] = [re.sub("[^A-Za-z]", "", b) for b, a in itertools.groupby(df['Col1'])]
df['Col1'] = [re.sub("[^0-9]", "", b) for b, a in itertools.groupby(df['Col1'])]
print(df)
Output:
Col1 Col2
0 304
1 321 A
2 14
3 319 B
4 315
5 88
6 242 C
7 243
CodePudding user response:
I'm adding a slightly modified version of the accepted answer and a deep dive into how it works hoping it will benefit some users who are still learning Pandas - like myself. :)
The accepted answer can me simplified because the df.join() is not needed:
out = (df.pop('Col1')
.str.extractall('(\d )|([a-zA-Z] )')
.groupby(level=0).first()
.fillna('')
.set_axis(['Col1', 'Col2'], axis=1))
Continue reading if you want to see a breakdown of how the solution works.
Self-contained runnable code:
import pandas as pd
import itertools
df = pd.DataFrame({'Col1': ['304', '321A', '14', '319B', '315', '88', '242C', '243']})
# print(df)
# Col1
# 0 304
# 1 321A
# 2 14
# 3 319B
# 4 315
# 5 88
# 6 242C
# 7 243
# Start with the given given data column
col1 = df['Col1'] # Equivalent to df.pop('Col1')
# print(col1)
# 0 304
# 1 321A
# 2 14
# 3 319B
# 4 315
# 5 88
# 6 242C
# 7 243
# Split the data into two columns based on the groups of
# the given regular expression.
# Docs:
# https://pandas.pydata.org/docs/reference/api/pandas.Series.str.extractall.html
split = col1.str.extractall('(\d )|([a-zA-Z] )')
# print(split)
# 0 1
# split
# e 0 304 NaN
# 1 0 321 NaN
# 1 NaN A
# 2 0 14 NaN
# 3 0 319 NaN
# 1 NaN B
# 4 0 315 NaN
# 5 0 88 NaN
# 6 0 242 NaN
# 1 NaN C
# 7 0 243 NaN
# split, above, has a multi-level index so we
# group by the first level (0) and specify that
# we wnat the first() (and ONLY) entry from
# each group. We could have used last().
# Docs:
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.groupby.html
grouping = split.groupby(level=0).first()
# print(grouping)
# 0 1
# 0 304 None
# 1 321 A
# 2 14 None
# 3 319 B
# 4 315 None
# 5 88 None
# 6 242 C
# 7 243 None
# Here we change the None values to empty strings.
noNones = grouping.fillna('')
#print(noNones)
# 0 1
# 0 304
# 1 321 A
# 2 14
# 3 319 B
# 4 315
# 5 88
# 6 242 C
# 7 243
# Finally we label axis 1 (the df columns)
out = noNones.set_axis(['Col1', 'Col2'], axis=1)
# print(out)
# Col1 Col2
# 0 304
# 1 321 A
# 2 14
# 3 319 B
# 4 315
# 5 88
# 6 242 C
# 7 243