Currently, my app is using NSRange in our data model, to represent the cursor position in UITextView.
Sometimes, we will generate NSRange to represent end of position/ end of string in UITextView.
This is our code to generate NSRange.
extension NSRange {
static func endOfStringFocused(_ string: String?) -> NSRange {
return NSRange(location: string?.count ?? 0, length: 0)
}
}
class ViewController: UIViewController {
@IBOutlet weak var textView: UITextView!
override func viewDidLoad() {
super.viewDidLoad()
textView.selectedRange = NSRange.endOfStringFocused(textView.text)
textView.becomeFirstResponder()
}
}
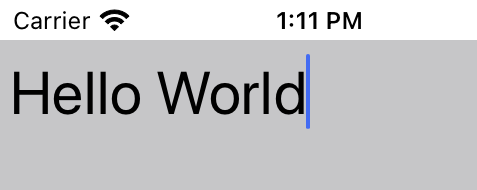
This is the outcome, when there is no emoji in the string. It works as expected because the cursor is now at the end of the string.
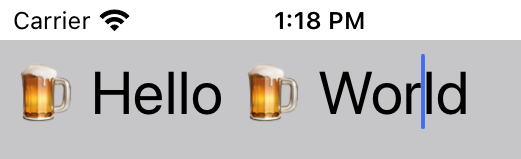
However, when there is non-english character (emoji) used, the outcome is incorrect. The cursor is no longer at the end of the string.
May I know, how to generate NSRange correctly for a given String to represent end of String?
CodePudding user response:
There are many ways. I recommend making a Swift Range<String.Index>, and convert it to an NSRange:
NSRange(string.endIndex..., in: string)
See also: NSRange from Swift Range?
The reason why the incorrect behaviour happens, is because the location property in NSRange counts a different thing (UTF-16 code units) than what the Swift String.count property counts (the number of Swift Characters, which are extended grapheme clusters, in the string). Therefore, to fix this, we can also just pass the correct number to NSRange(location:length:):
NSRange(location: string.utf16.count, length: 0)
// or
NSRange(location: (string as NSString).length, length: 0)
But I find these less intuitive than just converting the Swift range to NSRange.