I have a pandas dataframe where each row represents a resume, similar to:
| resume_id | resume_text | color_1 | color 2 |
|---|---|---|---|
| 1 | jane doe skills java driven ... | orange | red |
| 2 | john doe management excel... | red | green |
There is an id column, a preprocessed string column with the text of the resume, and 2 columns classifying the applicant's personality (coming from a personality test).
Now, I defined a function that randomly adds an X number of key words to the resume text. However, each color has a different associated list (list containing of typical key words for those personalities) to pull words from:
import random
def addKeyWords(string, color_list):
resume_word_count = len(string.split())
percentage = 0.05 # Percentage of total words that needs to be added
number_of_words_to_be_added = round(int(resume_word_count * percentage))
list_of_words = random.choices(color_list, k=number_of_words_to_be_added)
new_string = string " " " ".join(list_of_words)
return new_string
Now I want to loop through all the rows of the dataframe and apply the function based on the values of color_1 OR color_2.
For example, if either color_1 or color_2 == "orange" then apply the function such as:
df["resume_text_extra"] = df["resume_text"].apply(lambda x: addKeyWords(x, list_orange))
However, I can't get it to work with if-else statements within lambda. Any help would be appreciated!
CodePudding user response:
Check Below example code, using np.where. It applies lambda function based on the column value
import pandas as pd
import numpy as np
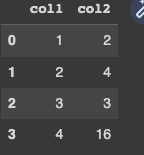
df = pd.DataFrame({'col1':[1,2,3,4]})
df['col2'] = np.where(df['col1']<=2, df['col1'].apply(lambda x: x * 2),
np.where( df['col1'] == 3, df['col1'],
df['col1'].apply(lambda x: x * 4)
))
df
Output:
CodePudding user response:
How about this?
condition = (df['color_1'] == 'orange') | (df['color_2'] == 'orange')
df[condition] = df[condition].apply(lambda x: addKeyWords(x, list_orange))