I have a data similar to this one:
my_data <- tibble(flower_color = c(rep("blue", 12), rep("red", 34), rep("pink", 19)),
flower_length = c(rep("short", 4), rep("medium", 15), rep("long", 12), rep("very long", 34)))
My aim is to create a stacked barplot representation, like this one:
table(my_data$flower_color, my_data$flower_length) %>%
as.data.frame() %>%
filter(Freq > 0) %>%
ggplot(aes(x = Var1, y = Freq, fill = Var2))
geom_bar(position = "fill", stat = "identity")
scale_y_continuous(labels = scales::percent_format())
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.background = element_blank(), axis.line = element_line(colour = "black"))
set_palette(q, "jco")
#stat_compare_means() # Global p-value
stat_compare_means(ref.group = "0.5", label = "p.signif",
label.y = c(22, 29))
My questions are:
- I would like to show on top of each bar the sample size for each blue, pink and red (e.g. on top of blue flower bar adding 12).
- Any suggestion about which statistical test I should use for checking if significative differences are present? And How can I add these results on my plot?
Thanks a lot for your precious help!
CodePudding user response:
I can't say whether this is the appropriate statistical test, but here is a potential solution:
library(tidyverse)
library(ggpubr)
library(ggsci)
my_data <- tibble(flower_color = c(rep("blue", 12),
rep("red", 34),
rep("pink", 19)),
flower_length = c(rep("short", 4),
rep("medium", 15),
rep("long", 12),
rep("very long", 34)))
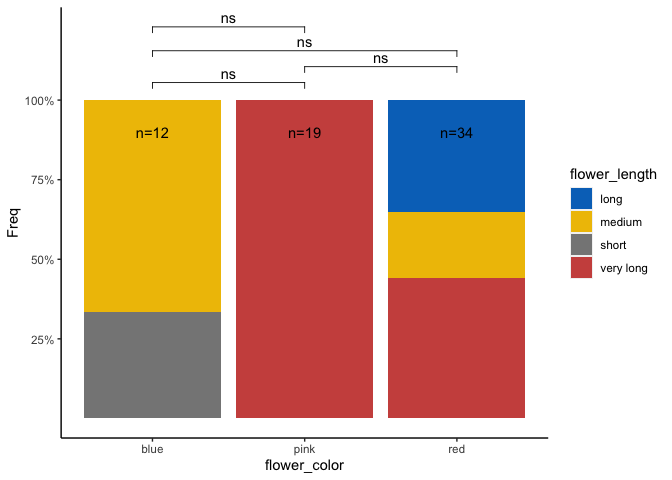
my_data %>%
group_by(flower_color, flower_length) %>%
summarise(Freq = n()) %>%
group_by(flower_color) %>%
mutate(Total = sum(Freq)) %>%
ggplot(aes(x = flower_color, y = Freq, fill = flower_length))
geom_bar(position = "fill", stat = "identity")
geom_text(aes(label = paste0("n=", Total), y = 0.9), check_overlap = TRUE)
scale_y_continuous(labels = scales::percent_format(),
breaks = c(0.25, 0.5, 0.75, 1))
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"))
fill_palette(palette = "jco")
stat_compare_means(comparisons = list(1:2, 2:3, c(1, 3), c(1, 2, 3)),
ref.group = 0.5, label.y = c(0.15, 0.2, 0.25, 0.325),
tip.length = 0.001, label = "p.signif")
#> `summarise()` has grouped output by 'flower_color'. You can override using the
#> `.groups` argument.
Created on 2022-08-24 by the reprex package (v2.0.1)