I am cleaning a dataset that contains multiple rows associated with the same user, with each row representing one time point. Each column is also tied to time point, such that there is a separate column for each question at each timepoint. The rest of the cells are blank. My data looks like this:
name<-rbind("Ang", "Ang", "Ang", "Bot", "Bot")
timepoint<-rbind("part 1", "part 2", "part 3", "part 1", "part 2")
q1<-rbind("More likely", "", "", "More likely", "")
q2<-rbind("", "Less likely", "", "", "More likely")
q3<-rbind("", "", "Less likely", "", "")
df<-cbind(name,timepoint, q1, q2, q3)
colnames(df)<-c("name", "timepoint", "answer_t1", "answer_t2", "answer_t3")
Such that the data looks like this:
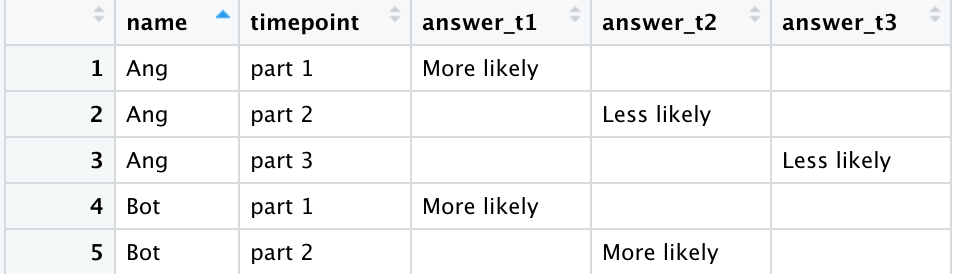
I need to consolidate the dataset so that there is one row per person.
I want the data to look like this:

The approaches I have seen before such as widening do not work for a dataset that has timepoint specific columns. I've tried an lapply solution like this: df[,lapply(.SD, paste0, collapse=""), by=name] but this has not worked for me.
Does anyone have any suggestions?
CodePudding user response:
For your example you could group_by(name) and take the max() for each column, e.g.
library(tidyverse)
name<-rbind("Ang", "Ang", "Ang", "Bot", "Bot")
timepoint<-rbind("part 1", "part 2", "part 3", "part 1", "part 2")
q1<-rbind("More likely", "", "", "More likely", "")
q2<-rbind("", "Less likely", "", "", "More likely")
q3<-rbind("", "", "Less likely", "", "")
df<-cbind(name,timepoint, q1, q2, q3)
colnames(df)<-c("name", "timepoint", "answer_t1", "answer_t2", "answer_t3")
df %>%
as.data.frame() %>%
group_by(name) %>%
mutate(across(starts_with("answer"), max)) %>%
select(-timepoint) %>%
distinct()
#> # A tibble: 2 × 4
#> # Groups: name [2]
#> name answer_t1 answer_t2 answer_t3
#> <chr> <chr> <chr> <chr>
#> 1 Ang More likely Less likely "Less likely"
#> 2 Bot More likely More likely ""
Created on 2022-08-24 by the reprex package (v2.0.1)
Does that solve your problem?
CodePudding user response:
Using data.table...
library(data.table)
dt <- as.data.table(df)
dt[, lapply(.SD, function(x) x[!is.na(x) & x != ""]) ,
by = .(name),
.SDcols = c("answer_t1", "answer_t2", "answer_t3")]
CodePudding user response:
In base R you could do
aggregate(.~name, subset(data.frame(df), select = -timepoint), max)
name answer_t1 answer_t2 answer_t3
1 Ang More likely Less likely Less likely
2 Bot More likely More likely
or even:
aggregate(.~name, data.frame(df)[-2], max)
name answer_t1 answer_t2 answer_t3
1 Ang More likely Less likely Less likely
2 Bot More likely More likely