I am working with a relatively big main branch. I create feature branches and merge them into the main branch. Most of such feature branches are orphan branches. Sometimes, I merge one upper-level main branch into a lower-level main branch (PROD to UAT) to align them together.
When doing git pull sometimes I forget to use the--rebase option, and I end up seeing annoying merge commits. I want to remove them.
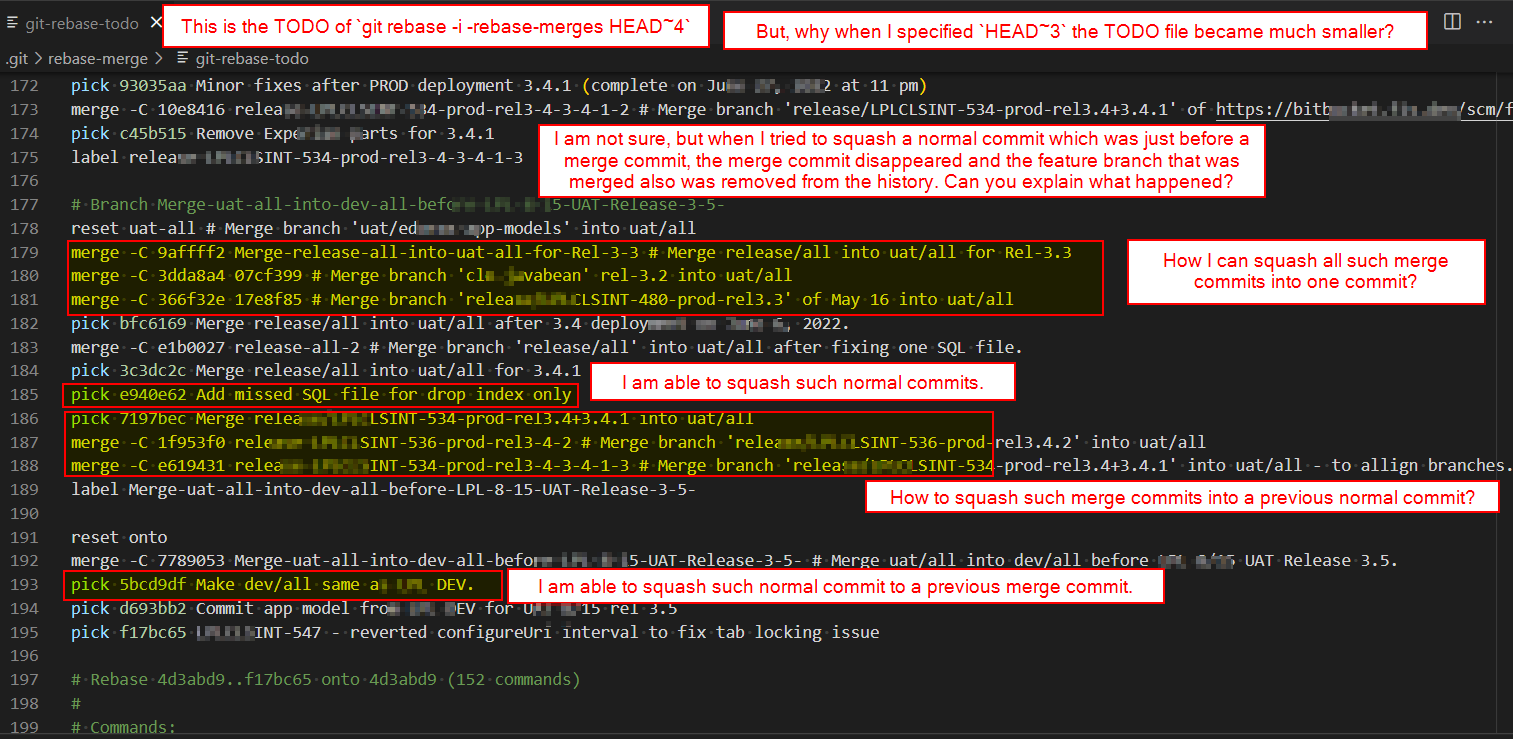
Please see the attached snapshot for this command TODO:
git rebase -i -rebase-merges HEAD~4
I have the following questions:
- Why did when I used this command instead
git rebase -i -rebase-merges HEAD~3, the TODO file became much smaller and only 3 or 4 items showed up in the file? - Not sure what I did exactly, when I tried to squash a normal commit which was just before a merge commit, the merge commit disappeared and the feature branch that was merged also was removed from the history. Can you explain what happened? I remember the process stopped, I had to resolve some conflicts, and do a commit, then continue the rebase.
- How I can squash the indicated merge commits into one normal commit or merge commit?
- How to squash the indicated merge commits into a previous normal commit?
- I want to understand more about the lines starting with
resetandlabel. Can you give some details or point me to a link to do more reading?
I appreciate your help.
CodePudding user response:
To set --rebase by default for git pull:
git config --global pull.rebase true
To view your history: use git log --graph --oneline
You can compare :
git log --graph --oneline HEAD~3..HEAD
# and
git log --graph --oneline HEAD~4..HEAD
(those are the commits selected by both your git rebase commands)
CodePudding user response:
Part 2 (link to part 1 here)
Rebasing with merges, with or without --rebase-merges
Suppose that instead of a simple:
...--o--*--P <-- main
\
F--G--H <-- feature (HEAD)
style branch setup at the start, we have this:
...--o--*--P <-- main
\
\ I--J
\ / \
F--G--H M--N <-- feature (HEAD)
\ /
K--L
That is, we have some branch-and-merge kind of thing happening in our feature branch. We now want to rebase feature onto commit P, as if we started our work there instead of at commit *.
A plain git rebase main will:
- paint
Pand*red; and - paint
NandMandJ-and-LandI-and-KandHandGandFgreen
and those would be our commits-to-be-copied. But regular rebase drops merge commits like M entirely, on purpose. The reason for this is that git cherry-pick literally cannot copy a merge commit like M. This "drop merges" happens in the same way that "drop commits that are copies" (except that it's much easier internally). We end up with:
F'-G'-H'-I'-J'-K'-L'-N' <-- feature (HEAD)
/
...--o--*--P <-- main
\
\ I--J
\ / \
F--G--H M--N [abandoned]
\ /
K--L
or, perhaps, the I-J and K-L order get switched around so that we have F'-G'-H'-K'-L'-I'-J'-N'.
The final snapshot in N' is just as good as the final snapshot in N was and the reason for this is that the merge commit M simply combined the work of I-J and K-L. When we used cherry-pick to copy each commit, one at a time, and flatten the merge away, we still got the same changes. *The fact that M is not an evil merge means that it was safe to omit it.
This obviously breaks if M is an evil merge. So perhaps evil merges are bad! That's why I said above that it's possible but usually a bad idea to squash an ordinary commit into a merge. The result is an evil merge and it gets dropped by this kind of git rebase.
What about --rebase-merges? Well, in this case, you get a much more complicated TODO worksheet:
I want to understand more about the lines starting with
resetandlabel. Can you give some details or point me to a link to do more reading?
What git rebase needs to do here is re-create merge commit M. The cherry-pick command still can't copy it, so instead of copying it, Git has to re-perform the merge.
The instruction sheet will now say:
- copy commits
F,G, andH: threepickcommands - save the hash ID of commit
H': onelabel - copy commits
IandJnow, and save the hash ID of commitJ', or copyKandLnow and saveL': one morelabel - switch back to commit
Husing the first label - copy the other two commits that we didn't copy yet
- some more stuff, but let's pause at this point to draw what we have.
At this point in our copying-commits-to-new-and-improved-commits process, we have this:
I'-J' [labeled and possibly HEAD]
/
F'-G'-H' [labeled]
/ \
/ K'-L' [labeled and possibly HEAD]
/
...--o--*--P <-- main
\
\ I--J
\ / \
F--G--H M--N <-- feature
\ /
K--L
We had to label commit H' so that we could reset to it. We had to label at least one of commits J' and L' so that we could find it again—whichever isn't HEAD. It's easier to just label both, and there's a reason to do that anyway, as we're about to see.
We're now ready to make M', our "copy" of M. We can't use cherry-pick at all; we have to run git merge. We'd like it to re-use the commit message from commit M, so we get a merge -C <hash> <label>, where the hash ID is that of the original merge, and the label is the commit we want merged in. Since the order of the two commits matters, we may need start with a reset to make sure HEAD selects commit J' now, if we're on L'. If we do, we need a label for J' to reset to. We don't know what the hash ID of J' will be at the time we generate the TODO list.
Anyway, we now reset to the appropriate first commit, and git merge the second one, to produce M'. Then we're ready to cherry-pick N' and that's the last operation before the rebase can finish on its own by moving the name feature:
I'-J'
/ \
F'-G'-H' M'-N' <-- feature (HEAD)
/ \ /
/ K'-L'
/
...--o--*--P <-- main
\
\ I--J
\ / \
F--G--H M--N [abandoned]
\ /
K--L
Note that the git merge that builds commit M does a new merge. Again, this is safe because—or more precisely, if—commit M is not an evil merge. So --rebase-merges doesn't save us from the error of making an evil merge.
Getting back to your first question
We can now finally also answer this:
Why did when I used this command instead
git rebase -i --rebase-merges HEAD~3, the TODO file became much smaller and only 3 or 4 items showed up in the file?
The red-and-green-paint trick determines which commits are to be copied. This doesn't depend on the --rebase-merges flag, which—as we saw above—just selects whether Git should re-perform merges, or flatten them away.
It really sounds like you want to flatten away your merges. To do that, don't use --rebase-merges. However, note that the red/green-paint thing can get tricky. In particular, git rebase only lets you pick one commit to select-with-history, to apply "red paint" from there on back.
You will always get the "green paint" applied to whichever commit is HEAD when you run git rebase, plus other commits selected because of the "with history" style selection.4 Remember that the commits are the history, and a git merge that you did in the past becomes a branch when we scan backwards, the way Git does.
4Caveat: if you run git rebase --onto X Y Z or git rebase Y Z, the operation start with a git switch Z, and that's the commit that HEAD selects. This is exactly equivalent to running git switch Z first, and then running git rebase --onto X Y or git rebase Y, including the fact that when the rebase completes, you're "on" branch Z.
CodePudding user response:
Part 1 (link to part 2 here)
You cannot squash a merge commit. There's a simple reason for this: a merge commit is, by definition, a commit with two parents. Squashing two commits together means that you'd like to replace two ordinary (i.e., single-parent) commits with one ordinary commit. As a merge commit is not an ordinary commit, it's simply not eligible for squashing.
As a rather special case, it is possible—but usually a bad idea—to squash an ordinary commit into a merge commit. This produces what is known as an evil merge: see Evil merges in git?
Why did when I used this command instead
git rebase -i -rebase-merges HEAD~3, the TODO file became much smaller and only 3 or 4 items showed up in the file?
Rebase is about copying commits to new and improved (or at least, presumably-improved) commits. Having copied those commits, you then direct your Git software to stop using the originals and start using the copies instead.
Only ordinary commits can be copied this way. However, there is a new-ish --rebase-merges option (side note: the double hyphen here is required; you can use -r as a synonym to avoid having to type a double hyphen), first available in Git 2.22, with numerous fixes and improvements in later versions. This tells Git to re-perform the specified merges. To get rid of merges, you want to avoid performing them at all. This requires detailed understanding of how rebase works.
The argument you're using here, HEAD~3 or HEAD~4, specifies which commits not to copy. Without this information Git would have to assume that you mean to copy every reachable commit (git rev-list --count HEAD would tell you how many commits that is, but it's probably hundreds or thousands). This argument is required unless you use --root to tell Git that it should copy every reachable commit (usually a bad idea, which is why rebase --root was not in Git for many years, until 1.7.12 was released in 2012).
Understanding commits
Getting all of this stuff into your head is a pretty big commitment (if I may use the word commit here). Still, it's important to do it. Remember that a repository itself is primarily a big box full of commits, so it's very important to know what each commit is and how they work, individually and together. More precisely, the two fundamental components of any Git repository are an objects database, which holds commit objects and other supporting objects, and a names database, which holds branch and tag and other names.
We start here with the objects, most specifically the commits. (The other three object types—tree, blob, and annotated-tag—are not in your face the way commits are: they mostly just work and you don't have to know the details, the way you do for commits). Every Git object is numbered, with a big ugly random-looking hash ID, or more formally an object ID or OID. These objects IDs can often be abbreviated, e.g., to the 4d3abd9 that appears in your image, but each one is actually 40 characters long (20 bytes or 160 bits), at least today. (Future versions of Git will someday have 256-bit = 64 character OIDs.)
For commits in particular, each commit gets a unique hash ID, at the time you (or whoever) make the commit. That one hash ID is now reserved forever, in every Git repository, even ones that do not yet exist, to mean that particular commit. This literally cannot work forever, and someday Git will break, but the sheer size of the hash ID is intended to put that day so far into the future (billions of years or more) that we don't care about this. To make this work as well as it does—which in practice, is just fine, even though it's theoretically rubbish—no part of any object can ever be changed. The trick by which Git ensures that other Gits that have never seen your new commit yet, and have no communications link to your repository, have already reserved that hash ID, is to use a cryptographic checksum of the commit content, and that trick only works if the content cannot be changed.1 That's currently the SHA-1 hash.
So: a commit is a numbered entity, found in Git's objects database—a simple key-value store with a hash ID as the key—by looking up its hash ID. Git desperately needs the hash ID to find the commit. Without that hash ID, Git is helpless. That's why you keep seeing them.
But what's in a commit? What good is a commit? The answer is simple, and two-fold:
A commit stores (indirectly) a full snapshot of every file. More precisely, it stores a full snapshot of every file Git was told to store, at the time you, or whoever, made the commit. As with all objects, this snapshot is completely read-only. For multiple purposes, the files are stored in a special form in which their content is compressed and de-duplicated. The de-duplication takes care of the obvious objection, that if every commit stores every file every time, the repository will become hugely bloated. As long as most commits mostly re-use most of the files from one or more previous commits, those files take literally no space at all, because they're de-duplicated away.
A commit also stores (directly) some metadata, or information about the commit itself. This is the only part of a commit that must occupy some space, and it's pretty tiny: it holds the name and email address of the person who made the commit, for instance, and some date-and-time-stamps and the log message. If your log message is not crazy long, the uncompressed commit is probably no more than a few hundred bytes (and then it gets compressed too).
Crucially for Git itself, the metadata for any given commit also stores a list of hash IDs. This list is usually just one entry long, which makes this commit an ordinary commit, with a single parent. The hash ID stored in the commit, in its metadata, is the hash ID of the parent of this commit, i.e., the commit that comes just before this one.
At least one commit in any non-empty repository is special because it has no parent: it's the first commit and it therefore is a root commit instead of an ordinary commit. It still has a full snapshot, just like any commit. It's possible to make extra root commits, using git checkout --orphan or git switch --orphan, but that's usually a bad idea. (You mentioned that you are using "orphan branches", and that's usually a bad idea, as we'll see.)
Some commits have more than one parent, which makes them merge commits. A merge commit still has just the single snapshot, like any other commit. Most merge commits have exactly two parents—some version control systems require this (e.g., Mercurial) but since Git has a list of parents, Git allows any integer ≥ 2 here. A multi-parent merge does not do anything that a two-parent merge couldn't do—in fact, it's kind of the reverse: a two-parent merge can do things that a 3 -parent merge can't. So they can be used for tying together multiple features. In my own opinion, though, they're mostly for showing off.