I am relatively new to Pandas. I need help with splitting certain sections of columns and organizing them into different sections (countries sorted into regions). I tried some methods I thought of and it did not work, here is the code I started from.
import pandas as pd
df = pd.read_csv('countries.csv')
countrieslist = {
'Asia': list(df.columns.values),
'Europe': list(df.columns.values),
'Others': list(df.columns.values)
}
print(f"Countries in Asia - {countrieslist['Asia']}")
print(f"Countries in Europe - {countrieslist['Europe']}")
print(f"Countries in Others - {countrieslist['Others']}")
I tried outputting the code above, and the output result is
Countries in Asia - [' ', ' Brunei Darussalam ', ' Indonesia ', ' Malaysia ', ' Philippines ', ' Thailand ', ' Viet Nam ', ' Myanmar ', ' Japan ', ' Hong Kong ', ' China ', ' Taiwan ', ' Korea, Republic Of ', ' India ', ' Pakistan ', ' Sri Lanka ', ' Saudi Arabia ', ' Kuwait ', ' UAE ', ' United Kingdom ', ' Germany ', ' France ', ' Italy ', ' Netherlands ', ' Greece ', ' Belgium & Luxembourg ', ' Switzerland ', ' Austria ', ' Scandinavia ', ' CIS & Eastern Europe ', ' USA ', ' Canada ', ' Australia ', ' New Zealand ', ' Africa ']
What the output should be:
Countries in Asia - ' Brunei Darussalam ', ' Indonesia ', ' Malaysia ', '
Philippines ', ' Thailand ', ' Viet Nam ', ' Myanmar ', ' Japan ', ' Hong Kong ', '
China ', ' Taiwan ', ' Korea, Republic Of ', ' India ', ' Pakistan ', ' Sri Lanka ', '
Saudi Arabia ', ' Kuwait ', ' UAE '
Countries in Europe - ' United Kingdom ', ' Germany ', ' France ', ' Italy ', '
Netherlands ', ' Greece ', ' Belgium & Luxembourg ', ' Switzerland ', ' Austria ', '
Scandinavia ', ' CIS & Eastern Europe '
Countries in Others – ' USA ', ' Canada ', ' Australia ', ' New Zealand ', ' Africa '
More info: this is the output of print(df.columns):
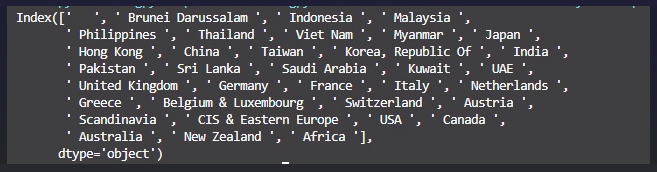
CodePudding user response:
I presume if you run df.columns, you will get an array like this:
[' ', ' Brunei Darussalam ', ' Indonesia ', ' Malaysia ', ' Philippines ', ' Thailand ', ' Viet Nam ', ' Myanmar ', ' Japan ', ' Hong Kong ', ' China ', ' Taiwan ', ' Korea, Republic Of ', ' India ', ' Pakistan ', ' Sri Lanka ', ' Saudi Arabia ', ' Kuwait ', ' UAE ', ' United Kingdom ', ' Germany ', ' France ', ' Italy ', ' Netherlands ', ' Greece ', ' Belgium & Luxembourg ', ' Switzerland ', ' Austria ', ' Scandinavia ', ' CIS & Eastern Europe ', ' USA ', ' Canada ', ' Australia ', ' New Zealand ', ' Africa ']
So your dictionary definition should be:
cols = [e.strip() for e in list(df.columns)]
countrieslist = {
'Asia': cols[ 1:19],
'Europe': cols[19:30],
'Others': cols[30: ]
}
What I have here, cols is a list of country names, and I'm slicing it using each name's index in this format: cols[start:end]. Note that the start index is inclusive, whereas the end index is exclusive.
Alternatively you can skip the dictionary and print directly
print( f"Countries in Asia - {cols[ 1:19]}")
print(f"Countries in Europe - {cols[19:30]}")
print(f"Countries in Others - {cols[30: ]}")
Output:
Countries in Asia - ['Brunei Darussalam', 'Indonesia', 'Malaysia', 'Philippines', 'Thailand', 'Viet Nam', 'Myanmar', 'Japan', 'Hong Kong', 'China', 'Taiwan', 'Korea, Republic Of', 'India', 'Pakistan', 'Sri Lanka', 'Saudi Arabia', 'Kuwait', 'UAE']
Countries in Europe - ['United Kingdom', 'Germany', 'France', 'Italy', 'Netherlands', 'Greece', 'Belgium & Luxembourg', 'Switzerland', 'Austria', 'Scandinavia', 'CIS & Eastern Europe']
Countries in Others - ['USA', 'Canada', 'Australia', 'New Zealand', 'Africa']