I have the foll. dataframe:
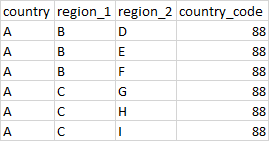
I want to add 2 new columns, region_1_code and region_2_code such that they are both 9 digit numbers. For region_1_code, it uniquely identifies each region_1 and is constructuted by first appending a 0 to the country_code is country_code is less than 100. Then the region_1's are alphabetically sorted and assigned a numeric code starting from 1 and followed by as many 0's as needed to reach a length of 6. Finally the country_code and the newly computed code are concatenated to get the region_1_code e.g. in this example, the region_1_code for region B is 880100000.
Similarly, region_2_code for region D will br 880100100. The final dataframe should look like this:
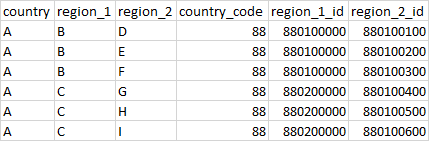
CodePudding user response:
This will give you the answer your looking for dynamically
df = pd.DataFrame({
'Country' : ['A', 'A', 'A', 'A', 'A', 'A'],
'Region_1' : ['B', 'B', 'B', 'C', 'C', 'C'],
'Region_2' : ['D', 'E', 'F', 'G', 'H', 'I'],
'Country_CD' : [88, 88, 88, 88, 88, 88]
})
df['Region_1_ID'] = df['Country_CD'].astype(str) '0'
df['Region_1_ID_Holder'] = df.groupby(['Country'])['Region_1'].transform(lambda x: x.factorize()[0] 1)
df['Region_1_ID_Holder'] = df['Region_1_ID_Holder'] * 100000
df['Region_1_ID'] = df['Region_1_ID'] df['Region_1_ID_Holder'].astype(str)
df['Region_2_ID'] = df['Country_CD'].astype(str) '0'
df['Region_2_ID_Holder'] = df.groupby(['Country'])['Country'].transform(lambda x: x.factorize()[0] 1)
df['Region_2_ID_Holder'] = df['Region_2_ID_Holder'] * 100
df['Region_2_ID_Count_Holder'] = df.groupby(['Country'])['Region_2'].cumcount() 1
df['Region_2_ID_Count_Holder'] = df['Region_2_ID_Count_Holder'] * 100
df['Region_2_ID'] = df['Region_2_ID'].astype(str) df['Region_2_ID_Holder'].astype(str) df['Region_2_ID_Count_Holder'].astype(str)
df = df.drop(columns = ['Region_1_ID_Holder', 'Region_2_ID_Holder', 'Region_2_ID_Count_Holder'])
df
However, this does not take into account if you have a Country_CD > 100, you could simply make this into a function and exclude those that are > 100
CodePudding user response:
Using groupby.cumcount:
df['region_1_id'] = (df.groupby('country')
.cumcount().add(1)
.add(df['country_code'].mul(100))
.mul(100000)
)
df['region_2_id'] = (df['region_1_id']
.add(df.groupby('country')
.cumcount().add(1)
.mul(100))
)
Output:
country region_1 region_2 country_code region_1_id region_2_id
0 A B D 88 880100000 880100100
1 A B E 88 880200000 880200200
2 A B F 88 880300000 880300300
3 A C G 88 880400000 880400400
4 A C H 88 880500000 880500500
5 A C I 88 880600000 880600600