A data frame as below:
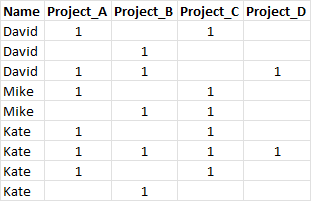
I want to find out the least 2 project names from the sum of projects'. Like:
David ['Project_C', 'Project_D']
Kate ['Project_B', 'Project_D']
Mike ['Project_A', 'Project_B', 'Project_D']
here is what I come up with:
import pandas as pd
from io import StringIO
csvfile = StringIO(
"""Name Project_A Project_B Project_C Project_D
David 1 1
David 1
David 1 1 1
Mike 1 1
Mike 1 1
Kate 1 1
Kate 1 1 1 1
Kate 1 1
Kate 1
""")
dict_p = {0 : 'Project_A',
1: 'Project_B',
2: 'Project_C',
3: 'Project_D'}
df = pd.read_csv(csvfile, sep = '\t', engine='python')
df = df.fillna(0)
df = df.groupby(['Name'])["Project_A", "Project_B", "Project_C", "Project_D"].apply(lambda x : x.astype(int).sum())
print (df)
# turn the interim result into a list, then index the smallest 2, and map from dict_p.
dict_from_df = df.set_index('Name').T.to_dict('list')
n_min_values = 2
for k,v in dict_from_df.items():
index_of_smallest_two = sorted(range(len(v)), key=lambda k: v[k])[:n_min_values]
C = (pd.Series(index_of_smallest_two)).map(dict_p)
final_list = list(C)
print (k, final_list)
Interim output:
Name Project_A Project_B Project_C Project_D
0 David 2 2 1 1
1 Kate 3 2 3 1
2 Mike 1 1 2 0
Final Output:
David ['Project_C', 'Project_D']
Kate ['Project_D', 'Project_B']
Mike ['Project_D', 'Project_A']
Mike is missing 'Project_B', but Mike's Project_A and Project_B are both of 1. i.e. it should be Mike ['Project_D', 'Project_A', 'Project_B']
How can I correct it?
Thank you.
CodePudding user response:
One way using pandas.DataFrame.apply with pandas.Series.nsmallest:
gdf = df.groupby("Name").sum()
new_df = gdf.apply(lambda x: list(x.nsmallest(2, keep="all").index), axis=1)
print(new_df)
Output:
Name
David [Project_C, Project_D]
Kate [Project_D, Project_B]
Mike [Project_D, Project_A, Project_B]
dtype: object