I have a time series data where I would like to calculate sum of 4 quarters and divide the result with a value in another column. Here is my data example. In reality I will have 10K rows.
df = pd.DataFrame({'c1':[20,15,10,12,15,17,19,20,9,10],'c2':[22,14,19,13,15,17,19,10,20,12]})
date_array=[[2019,12,31],[2019,9,30],[2019,6,30],[2019,3,31],[2018,12,31],[2018,9,30],[2018,6,30],[2018,3,31],[2017,12,31],[2017,9,30]]
date_df = pd.DataFrame(date_array, columns=['year', 'month', 'day'])
df['date'] = pd.to_datetime(date_df[['year', 'month', 'day']], format='%Y-%m-%d')
df = df[['date','c1','c2']]
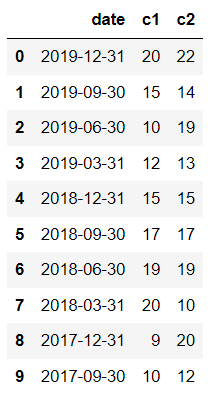
Now, I would like to create c3 column to store calculated values between c1 and c2. The expecting result will be
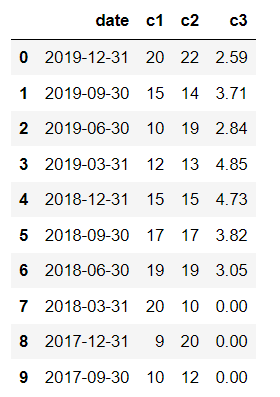
In first row, c3 = 2.59 comes from sum of first 4 rows in c1 (20 15 10 12) divided by first row in c2 (22)
In second row, c3 = 3.71 comes from sum of next 4 rows in c1 (15 10 12 15) divided by second row in c2 (14)
and so on..
Toward the end of dataframe, if we have less than 4 rows to calculate, just return 0.
Can anyone please guide me. I try to pick only 4 rows out but it doesn't work already.
for i in range(len(df)):
print(df.loc[i:i 3, "c1"])
CodePudding user response:
In your case just do rolling
df['new'] = df['c1'].iloc[::-1].rolling(4).sum()/df['c2']
Out[993]:
0 2.59090909
1 3.71428571
2 2.84210526
3 4.84615385
4 4.73333333
5 3.82352941
6 3.05263158
7 NaN
8 NaN
9 NaN
dtype: float64