I have two .CSV files:
One is a dataset with over 1500 features and 300 samples,
the second is an RFECV ranking of features:
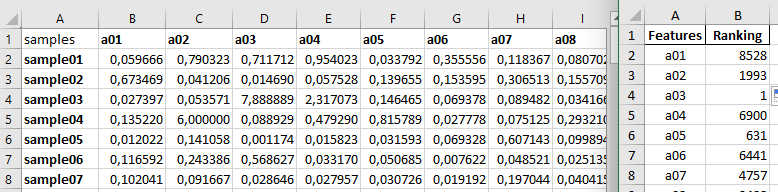
I'm trying to remove each column of a feature from the dataset, that does not have a ranking of 1.
So we only should have something like this:
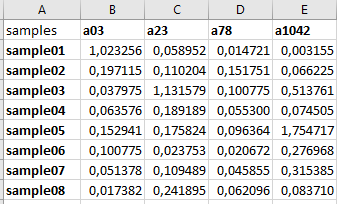
What would be the proper way of doing something like that in Python?
I was thinking of transposing the second array, finding the indexes with ones and moving columns with these indexes from the dataset to an another array.
CodePudding user response:
Try:
rank_1 = df2[df2.Ranking == 1].Features
new_df = df1[rank_1]
CodePudding user response:
import pandas as pd
df1 = pd.read_csv("path-to-first-csv-file.csv")
df2 = pd.read_csv("path-to-second-csv-file.csv")
result = df1[df2[df2["Ranking"] == 1]["Features"]]