Suppose we have a data frame with four columns, A, B, x, y as follows:
data = pd.DataFrame({
'A' : [1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3],
'B' : [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1],
'x' : [4, 4, 5, 5, 6, 6, 4, 4, 5, 5, 6, 6, 4, 4, 5, 5, 6, 6],
'y' : [166,171, 127, 150, 120, 185, 135, 152, 173,
192, 174, 185, 101, 102, 134, 100, 110, 143]
})
For each (x, A) pair we have two values of y. I would like to create a bar plot of the total y versus x, with A column determining the categories, while designating what portion of total y is coming from B == 1. An incomplete solution
agg = data.groupby(['A', 'x'])['y'].sum().to_frame().reset_index()
seaborn.barplot(data=agg, x='x', y='y', hue='A', alpha=0.5)
seaborn.barplot(data=data[data.B==1], x='x', y='y', hue='A')
which yields:
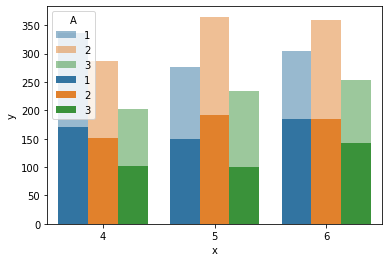
The issue is the double legend. I am looking for a way to drop the legend after the first first barplot call while keeping the one from the second.
CodePudding user response:
You can use a "hack" and get your categories as strings starting with an underscore in the first plot. The labels will be hidden:
import seaborn
agg = data.groupby(['A', 'x'])['y'].sum().to_frame().reset_index()
seaborn.barplot(data=agg.assign(A='_' agg['A'].astype(str).str.zfill(3)),
x='x', y='y', hue='A', alpha=0.5)
seaborn.barplot(data=data[data.B==1], x='x', y='y', hue='A')
output:
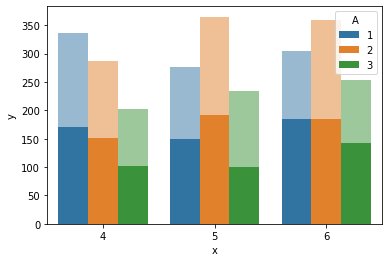
"hacked" input (using zfill(3) to handle up to 999 sorted categories):
A x y
0 _001 4 337
1 _001 5 277
2 _001 6 305
3 _002 4 287
4 _002 5 365
5 _002 6 359
6 _003 4 203
7 _003 5 234
8 _003 6 253
Other option, rework the legend afterwards:
import seaborn
agg = data.groupby(['A', 'x'])['y'].sum().to_frame().reset_index()
seaborn.barplot(data=agg, x='x', y='y', hue='A', alpha=0.5)
seaborn.barplot(data=data[data.B==1], x='x', y='y', hue='A')
h, l = plt.gca().get_legend_handles_labels()
plt.legend(h[3:], l[3:])