Consider the following data:
, Animal, Color, Rank, X
0, c, b, 1, 9
1, c, b, 2, 8
2, c, b, 3, 7
3, c, r, 1, 6
4, c, r, 2, 5
5, c, r, 3, 4
6, d, g, 1, 3
7, d, g, 2, 2
8, d, g, 3, 1
I now want to group by ["Animal", "Color"] and, for every group, I want to subtract the X value that corresponds to Rank equal to 1 from every other X value in that group.
Currently I am looping like this:
dfs = []
for _, tmp in df.groupby(["Animal","Color"]):
baseline = tmp.loc[tmp["Rank"]==1,"X"].to_numpy()
tmp["Y"] = tmp["X"]-baseline
dfs.append(tmp)
dfs = pd.concat(dfs)
This yields the right result, i.e.,
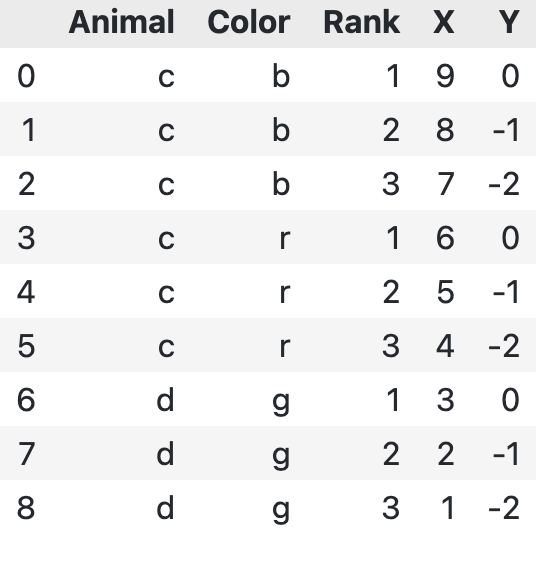
The whole process is however really slow and I would prefer to use apply or transform instead.
My problem is that I am unable to find a way to use the whole grouped data within apply or transform.
Is there a way to accelerate my computation?
For completeness, here's my MWE:
df = pd.DataFrame(
{
"Animal": {0: "c", 1: "c", 2: "c", 3: "c", 4: "c", 5: "c", 6: "d", 7: "d", 8: "d"},
"Color": {0: "b", 1: "b", 2: "b", 3: "r", 4: "r", 5: "r", 6: "g", 7: "g", 8: "g"},
"Rank": {0: 1, 1: 2, 2: 3, 3: 1, 4: 2, 5: 3, 6: 1, 7: 2, 8: 3},
"X": {0: 9, 1: 8, 2: 7, 3: 6, 4: 5, 5: 4, 6: 3, 7: 2, 8: 1},
}
)
CodePudding user response:
Maybe it's the same as OP's solution performance-wise, but a little bit shorter:
# Just to be sure that we won't mess up the ordering after groupby
df.sort_values(['Animal', 'Color', 'Rank'], inplace=True)
df['Y'] = df['X'] - df.groupby(['Animal', 'Color']).transform('first')['X']
CodePudding user response:
I think I found a solution that is faster (at least in my use case):
# get a unique identifier for every group
df["_group"] = df.groupby(["Animal", "Color"]).ngroup()
# for every group, get that identifier and the value X to be subtracted
baseline = df.loc[df["Rank"] == 1, ["_group", "X"]]
# merge the original data and the baseline data on the group
# this gives a new column with the Rank==1 value of X
df = pd.merge(df, baseline, on="_group", suffixes=("", "_baseline"))
# perform arithmetic
df["Y"] = df["X"] - df["X_baseline"]
# drop intermediate columns
df.drop(columns=["_group", "X_baseline"], inplace=True)