I would like to extract all values from dataframe that are non zero and write these data into separate column (with header name and value).
I was able to find a solution via Excel:
=TRANSPOSE(INDEX(IF(MOD(SEQUENCE(2),2),FILTER(C$1:H$1,C2:H2<>0),FILTER(C2:H2,C2:H2<>0)),MOD(SEQUENCE(COUNTIF(C2:H2,"<>0")*2)-1,2) 1,ROUNDUP(SEQUENCE(COUNTIF(C2:H2,"<>0")*2)/2,0)))
But I would like to do it using Python.
Input data:
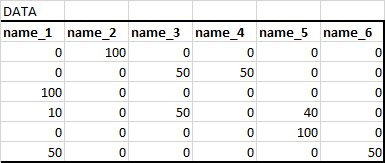
Desired output:

CodePudding user response:
Simple solution
Just walkthrough columns:
df = pd.DataFrame({
"a": [0, 0, 2, 0, 3],
"b": [0, 1, 1, 0, 1]
})
result = [df[col][df[col] != 0] for col in df.columns]
print(*result)
Output (non-zero series for each column):
2 2
4 3
Name: a, dtype: int64 1 1
2 1
4 1
Name: b, dtype: int64
It's a series, where value is value (2, 3), index is index of non-zero elements (2, 4) and name of series is name.
CodePudding user response:
You can use defaultdict to keep occurrences and values:
try:
d = defaultdict(list)
for row, val in df.iterrows():
for col in range(len(df.columns)):
if val[col] != 0:
d[row 1].append((col 1, val[col]))
for i in range(max(len(x) for x in d.values())):
df['occurrence ' str(i 1)] = ['name_' str(list(d.values())[j][i][0]) if i<len(d[j 1]) else None for j in range(len(d))]
df['value ' str(i 1)] = [str(list(d.values())[j][i][1]) if i<len(d[j 1]) else None for j in range(len(d))]
to replicate everything:
import pandas as pd
import numpy as np
from collections import defaultdict
data = {'name_1': {0: 0, 1: 0, 2: 100, 3: 10, 4: 0, 5: 50},
'name_2': {0: 100, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0},
'name_3': {0: 0, 1: 50, 2: 0, 3: 50, 4: 0, 5: 0},
'name_4': {0: 0, 1: 50, 2: 0, 3: 0, 4: 0, 5: 0},
'name_5': {0: 0, 1: 0, 2: 0, 3: 40, 4: 100, 5: 0},
'name_6': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 50}}
df = pd.DataFrame(data)
d = defaultdict(list)
for row, val in df.iterrows():
for col in range(len(df.columns)):
if val[col] != 0:
d[row 1].append((col 1, val[col]))
for i in range(max(len(x) for x in d.values())):
df['occurrence ' str(i 1)] = ['name_' str(list(d.values())[j][i][0]) if i<len(d[j 1]) else None for j in range(len(d))]
df['value ' str(i 1)] = [str(list(d.values())[j][i][1]) if i<len(d[j 1]) else None for j in range(len(d))]