I am looking to automate some work I have been doing in PowerPoint/Excel using Python and MatPlotLib; however, I am having trouble recreating what I have been doing in PowerPoint/Excel.
I have three data series that are grouped by month on the x-axis; however, the months are not date/time and have no real x-values. I want to be able to assign x-values based on the number of rows (so they are not stacked), then group them by month, and add a vertical line once the month "value" changes.
It is also important to note that the number of rows per month can vary, so im having trouble grouping the months and automatically adding the vertical line once the month data changes to the next month.
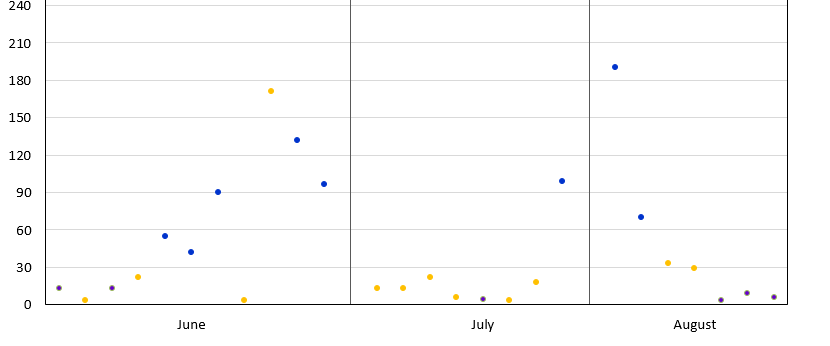
Here is a sample image of what I created in PowerPoint/Excel and what I am hoping to accomplish:
Here is what I have so far:
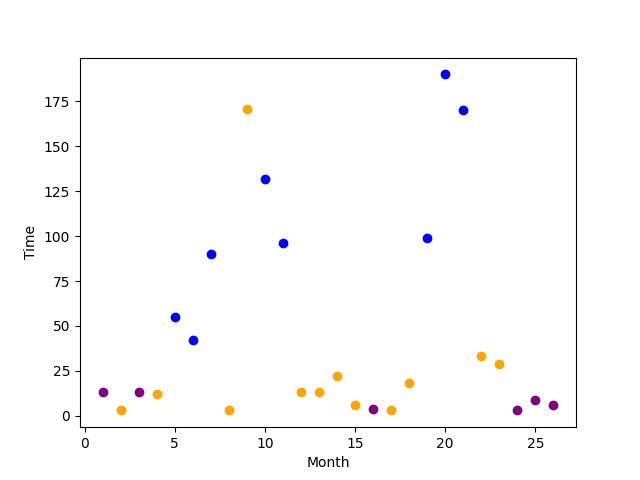
For above: I added a new column to my csv file named "Count" and added that as my x-values; however, that is only a workaround to get my desired "look" and does not separate the points by month.
My code so far:
manipulate.csv
Count,Month,Type,Time
1,June,Purple,13
2,June,Orange,3
3,June,Purple,13
4,June,Orange,12
5,June,Blue,55
6,June,Blue,42
7,June,Blue,90
8,June,Orange,3
9,June,Orange,171
10,June,Blue,132
11,June,Blue,96
12,July,Orange,13
13,July,Orange,13
14,July,Orange,22
15,July,Orange,6
16,July,Purple,4
17,July,Orange,3
18,July,Orange,18
19,July,Blue,99
20,August,Blue,190
21,August,Blue,170
22,August,Orange,33
23,August,Orange,29
24,August,Purple,3
25,August,Purple,9
26,August,Purple,6
testchart.py
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('manipulate.csv')
df=df.reindex(columns=["Month", "Type", "Time", "Count"])
df['Orange'] = df.loc[df['Type'] == 'Orange', 'Time']
df['Blue'] = df.loc[df['Type'] == 'Blue', 'Time']
df['Purple'] = df.loc[df['Type'] == 'Purple', 'Time']
print(df)
w = df['Count']
x = df['Orange']
y = df['Blue']
z = df['Purple']
plt.plot(w, x, linestyle = 'none', marker='o', c='Orange')
plt.plot(w, y, linestyle = 'none', marker='o', c='Blue')
plt.plot(w, z, linestyle = 'none', marker='o', c='Purple')
plt.ylabel("Time")
plt.xlabel("Month")
plt.show()
CodePudding user response:
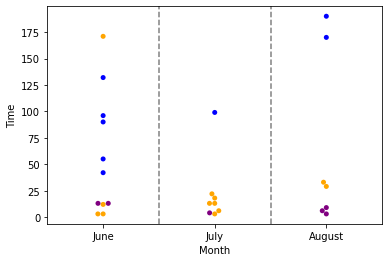
Can I suggest using Seaborn's swarmplot instead? It might be easier:
import seaborn as sns
import matplotlib.pyplot as plt
# Change the month to an actual date then set the format to just the date's month's name
df.Month = pd.to_datetime(df.Month, format='%B').dt.month_name()
sns.swarmplot(data=df, x='Month', y='Time', hue='Type', palette=['purple', 'orange', 'blue'])
plt.legend().remove()
for x in range(len(df.Month.unique())-1):
plt.axvline(0.5 x, linestyle='--', color='black', alpha = 0.5)
Output Graph:
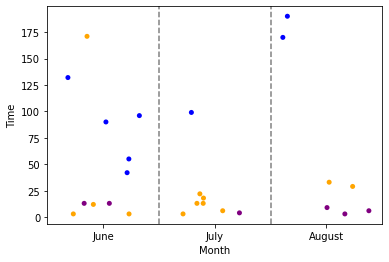
Or Seaborn's stripplot with some jitter value:
import seaborn as sns
import matplotlib.pyplot as plt
# Change the month to an actual date then set the format to just the date's month's name
df.Month = pd.to_datetime(df.Month, format='%B').dt.month_name()
sns.stripplot(data=df, x='Month', y='Time', hue='Type', palette=['purple', 'orange', 'blue'], jitter=0.4)
plt.legend().remove()
for x in range(len(df.Month.unique())-1):
plt.axvline(0.5 x, linestyle='--', color='black', alpha = 0.5)
If not, this answer will use matplotlib.dates's mdates to format the labels of the xaxis to just the month names. It will also use datetime's timedelta to add some days to each month to split them up (so that they are not overlapped):
from datetime import timedelta
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
df.Month = pd.to_datetime(df.Month, format='%B')
separators = df.Month.unique() # Get each unique month, to be used for the vertical lines
# Add an amount of days to each value within a range of 25 days based on how many days are in each month in the dataframe
# This is just to split up the days so that there is no overlap
dayAdditions = sum([list(range(2,25,int(25/x))) for x in list(df.groupby('Month').count().Time)], [])
df.Month = [x timedelta(days=count) for x,count in zip(df.Month, dayAdditions)]
df=df.reindex(columns=["Month", "Type", "Time", "Count"])
df['Orange'] = df.loc[df['Type'] == 'Orange', 'Time']
df['Blue'] = df.loc[df['Type'] == 'Blue', 'Time']
df['Purple'] = df.loc[df['Type'] == 'Purple', 'Time']
w = df['Count']
x = df['Orange']
y = df['Blue']
z = df['Purple']
fig, ax = plt.subplots()
plt.plot(df.Month, x, linestyle = 'none', marker='o', c='Orange')
plt.plot(df.Month, y, linestyle = 'none', marker='o', c='Blue')
plt.plot(df.Month, z, linestyle = 'none', marker='o', c='Purple')
plt.ylabel("Time")
plt.xlabel("Month")
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonthday=15)) # Set the locator at the 15th of each month
ax.xaxis.set_major_formatter(mdates.DateFormatter('%B')) # Set the format to just be the month name
for sep in separators[1:]:
plt.axvline(sep, linestyle='--', color='black', alpha = 0.5) # Add a separator at every month starting at the second month
plt.show()
Output:
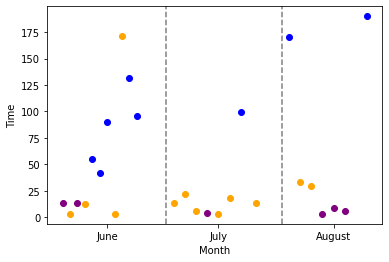
This is how I put your data in a df, in case anyone else wants to grab it to help answer the question:
from io import StringIO
import pandas as pd
TESTDATA = StringIO(
'''Count,Month,Type,Time
1,June,Purple,13
2,June,Orange,3
3,June,Purple,13
4,June,Orange,12
5,June,Blue,55
6,June,Blue,42
7,June,Blue,90
8,June,Orange,3
9,June,Orange,171
10,June,Blue,132
11,June,Blue,96
12,July,Orange,13
13,July,Orange,13
14,July,Orange,22
15,July,Orange,6
16,July,Purple,4
17,July,Orange,3
18,July,Orange,18
19,July,Blue,99
20,August,Blue,190
21,August,Blue,170
22,August,Orange,33
23,August,Orange,29
24,August,Purple,3
25,August,Purple,9
26,August,Purple,6''')
df = pd.read_csv(TESTDATA, sep = ',')
CodePudding user response:
Maybe add custom x-axis labels and separating lines between months:
new_month = ~df.Month.eq(df.Month.shift(-1))
for c in df[new_month].Count.values[:-1]:
plt.axvline(c 0.5, linestyle="--", color="gray")
plt.xticks(
(df[new_month].Count df[new_month].Count.shift(fill_value=0)) / 2,
df[new_month].Month,
)
for color in ["Orange", "Blue", "Purple"]:
plt.plot(
df["Count"],
df[color],
linestyle="none",
marker="o",
color=color.lower(),
label=color,
)
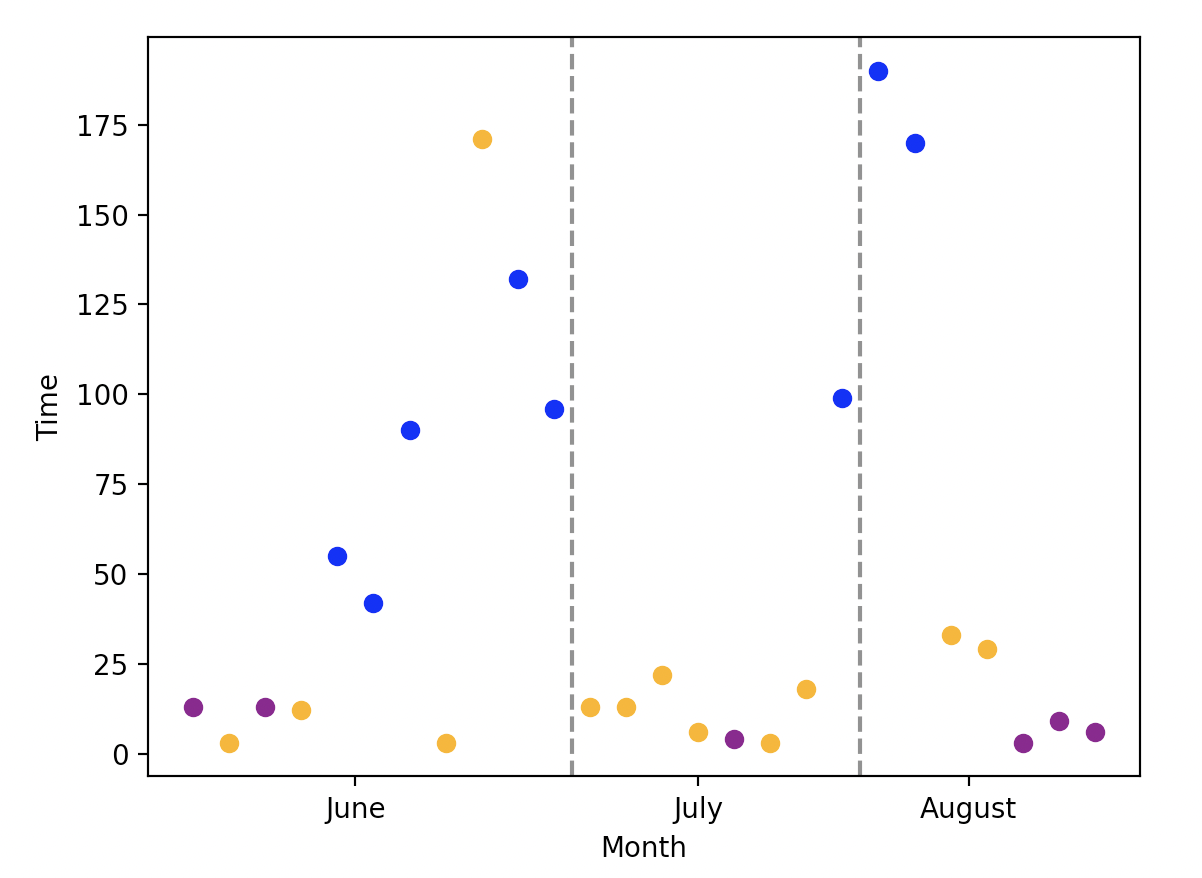
I would also advise that you rename the color columns into something more descriptive and if possible add more time information to your data sample (days, year).