I am hoping somebody will be able to tell me why I am doing wrong, please?
My code reads three Excel files: 0122.xls, 0222.xls and 0322.xls and merges them together in a data frame. My problem is that when I create a new column that should contain the original file's name I am expecting to get 0122.xls, 0222.xls and 0322.xls but getting something different and I can't pinpoint what I am doing wrong. USD 1.1 comes from file 0122, USD 1.2 from 0222.xls and file 0322 contains USD 1.3.
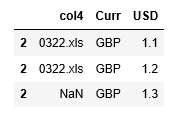
Any help would be appreciated! Here is my code. Thank you.
import pandas as pd
import numpy as np
import os
os.chdir('//.../Python/data')
path = '//.../Python/data'
files = os.listdir(path)
df = pd.DataFrame()
for f in files:
data = pd.read_excel(f, skiprows=np.r_[0:7], header=0, usecols=['Unnamed: 2','Unnamed: 3'])
df['col4'] = f
df = df.append(data)
df = df.rename(columns={'Unnamed: 2': 'Curr', 'Unnamed: 3': 'USD'})
df = df.drop(df[df.Curr != 'GBP'].index)
df
CodePudding user response:
In the for loop you should change
df['col4'] = f
to
data['col4'] = f
otherwise reasign all of col4 every iteration of the for loop, hence why it ends up with the name of the final file in every row.