I have a data frame with a column that has duplicates and I need to swap a position between as you see in my Dataframe the Position of 'Precondition' and the 'Test Case'.
What i want to do is to reorder the rows so the Column 'Type' gets 'Test Case', 'Precondition' and then 'Test Step'
I used the .copy() method but it deletes all the values in the rows
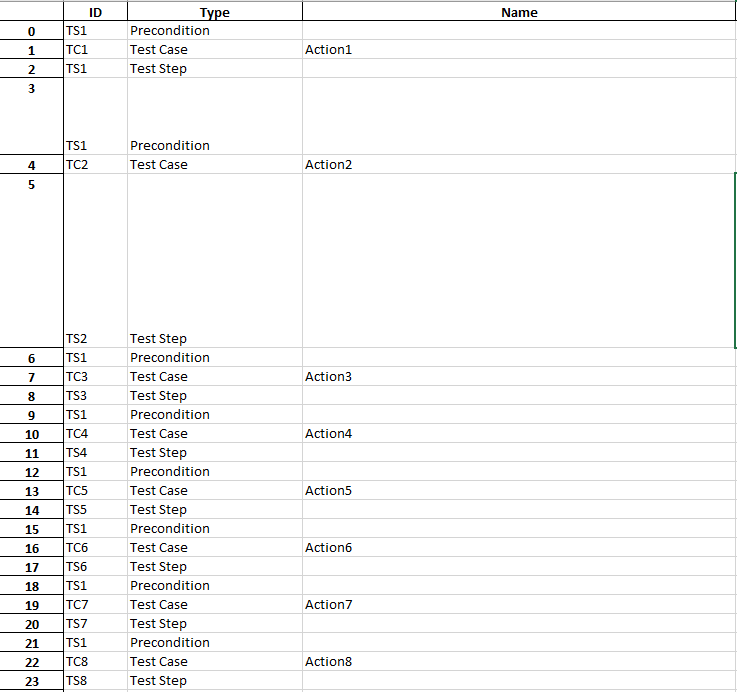
And here ist the Desiered Output:enter image description here
{kind=link}
CodePudding user response:
Set the priorities of your values (the sequence in which they should appear).
The code creates 2 temporary columns to sort by them both, after that drops them:
priorities = {'Test Case': 1, 'Precondition': 2, 'Test Step': 3}
df.assign(order = df.groupby('Type').cumcount(),
priorities = df['Type'].replace(priorities)
).sort_values(['order', 'priorities']).drop(columns=['order', 'priorities'])
Reference: Sort Pandas Dataframe on two columns with one column values repeating in sequence