I am currently trying to check if a number in a comma-separated string is within a number interval. What I am trying to do is to check if an area code (from the comma-separated string) is within the interval of an area.
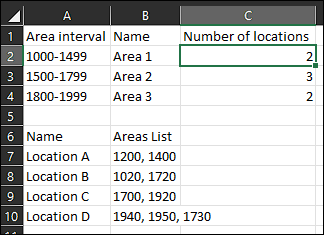
The data: AREAS
| Area interval | Name | Number of locations |
|---|---|---|
| 1000-1499 | Area 1 | ? |
| 1500-1799 | Area 2 | ? |
| 1800-1999 | Area 3 | ? |
GEOLOCATIONS
| Name | Areas List |
|---|---|
| Location A | 1200, 1400 |
| Location B | 1020, 1720 |
| Location C | 1700, 1920 |
| Location D | 1940, 1950, 1730 |
The result I want here is the number of unique locations in the "Areas list" within the area interval. So Location D should only count ONCE in the 1800-1999 "area", and the Location A the same in the 1000-1499 location. But location B should count as one in both 1000-1499 and one in 1500-1799 (because a number from each interval is in the comma-separated string in "Areas list"):
| Area interval | Name | Number of locations |
|---|---|---|
| 1000-1499 | Area 1 | 2 |
| 1500-1799 | Area 2 | 3 |
| 1800-1999 | Area 3 | 2 |
How is this possible?
I have tried with a COUNTIFS, but it doesnt seem to do the job.
CodePudding user response:
Here is one option using FILTERXML():
Formula in C2:
=SUM(FILTERXML("<x><t>"&TEXTJOIN("</s></t><t>",,"1<s>"&SUBSTITUTE(B$7:B$10,", ","</s><s>"))&"</s></t></x>","//t[count(.//*[.>="&SUBSTITUTE(A2,"-","][.<=")&"])>0]"))
Where //t[count(.//*[.>="&SUBSTITUTE(A2,"-","][.<=")&"])>0]")) basically means that we collect all t-nodes where the count of child s-nodes that are >= to the leftmost number and <= to the rightmost number is larger than zero. By default the returned locations should be unique based on your data.
Or, wrap the above in BYROW():
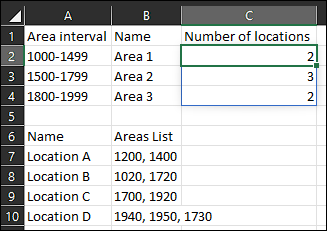
Formula in C2:
=BYROW(A2:A4,LAMBDA(a,SUM(FILTERXML("<x><t>"&TEXTJOIN("</s></t><t>",,"1<s>"&SUBSTITUTE(B$7:B$10,", ","</s><s>"))&"</s></t></x>","//t[count(.//*[.>="&SUBSTITUTE(a,"-","][.<=")&"])>0]"))))
CodePudding user response:
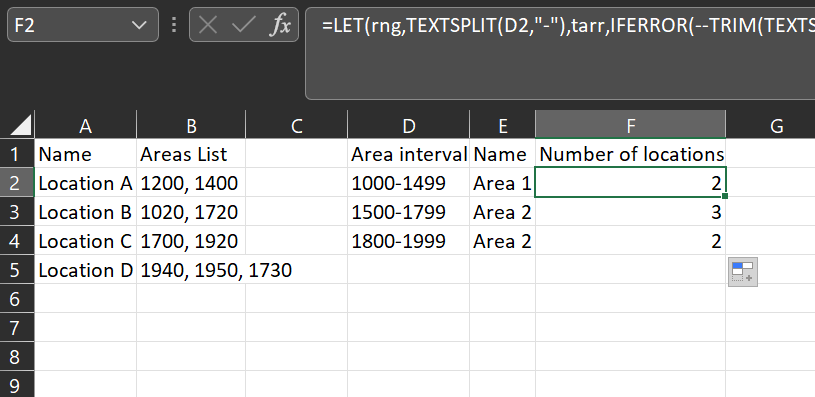
Using MMULT and TEXTSPLIT:
=LET(rng,TEXTSPLIT(D2,"-"),
tarr,IFERROR(--TRIM(TEXTSPLIT(TEXTJOIN(";",,$B$2:$B$5),",",";")),0),
SUM(--(MMULT((tarr>=--TAKE(rng,,1))*(tarr<=--TAKE(rng,,-1)),SEQUENCE(COLUMNS(tarr),,1,0))>0)))
CodePudding user response:
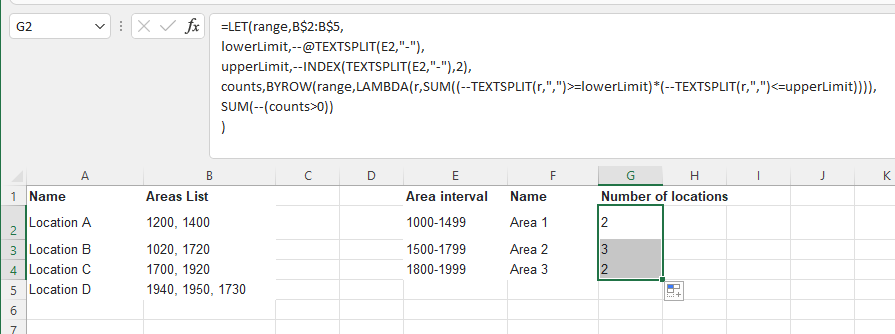
I am in very distinguished company but will add my version anyway as byrow probably is a slightly different approach
=LET(range,B$2:B$5,
lowerLimit,--@TEXTSPLIT(E2,"-"),
upperLimit,--INDEX(TEXTSPLIT(E2,"-"),2),
counts,BYROW(range,LAMBDA(r,SUM((--TEXTSPLIT(r,",")>=lowerLimit)*(--TEXTSPLIT(r,",")<=upperLimit)))),
SUM(--(counts>0))
)
CodePudding user response:
Here the ugly way to do it, with A LOT of helper columns. But not so complicated