How can I apply a custom function to each row of a Pandas dataframe df1, where:
- the function uses values from a column in
df1 - the function uses values from another dataframe
df2 - the results are appended to
df1column-wise
Example:
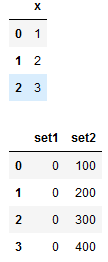
df1 = pd.DataFrame([1, 2, 3], columns=["x"])
df2 = pd.DataFrame({"set1": [0, 0, 0, 0], "set2": [100, 200, 300, 400]})
display(df1, df2)
And custom function
def myfunc(df2, x=df1["x"]):
# Something simple but custom
ans = df2["set1"] df2["set2"] * x
return ans
Desired output is
| x | run1 | run2 | run3 | run4 | |
|---|---|---|---|---|---|
| 0 | 1 | 100 | 200 | 300 | 400 |
| 1 | 2 | 200 | 400 | 600 | 800 |
| 2 | 3 | 300 | 600 | 900 | 1200 |
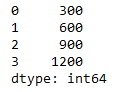
Here is an example function call; but how can I apply it with a oneliner to get the desired dataframe output?
test = myfunc(df2,x=3)
print(test)
CodePudding user response:
You can do
df1 = df1.join(df1.apply(lambda x : myfunc(df2, x['x']),axis=1))
Out[152]:
x 0 1 2 3
0 1 100 200 300 400
1 2 200 400 600 800
2 3 300 600 900 1200
CodePudding user response:
This is specific to your example myfunc but it is possible to vectorize with dot
df1[['x']].dot(
df2['set1'].add(df2['set2']).to_frame().T.values
).rename(
columns={i:f'run{i 1}' for i in df2.index}
).assign(
x = df1['x'],
)
CodePudding user response:
If you really need a custom function, you can use apply:
# Modified slightly to make using it easier~
def myfunc(x, df2):
return df2["set1"] df2["set2"] * x
df1 = df1.join(df1.x.apply(myfunc, args=(df2,)).add_prefix('run'))
print(df1)
# Output:
x run0 run1 run2 run3
0 1 100 200 300 400
1 2 200 400 600 800
2 3 300 600 900 1200
That said, there's often a way to do whatever you want to do using pandas methods:
df = df1.merge(df2, 'cross')
df['value'] = df.set1 df.set2 * df.x
df['run'] = df.groupby('x')['value'].cumcount() 1
df = df.pivot(index='x', columns='run', values='value')
df.columns = [f'{df.columns.name}{x}' for x in df.columns]
print(df.reset_index())
# Output:
x run1 run2 run3 run4
0 1 100 200 300 400
1 2 200 400 600 800
2 3 300 600 900 1200