I have a pandas data frame where the 'combined_id' column is basically a combination of the first two columns. I want to create the combined_id column such that the smaller number comes before the larger one. I know I can swap around the first two columns to be listed in order of smallest/largest, but I want the order of the first two cols to remain as they are.
what I have:
Student1 Student2 combined_id
id/USER321 id/USER329 id/USER321_USER329
id/USER123 id/USER123 id/USER123_USER123
id/USER439 id/USER122 id/USER439_USER122
id/USER999 id/USER333 id/USER999_USER333
Desired
Student1 Student2 combined_id
id/USER321 id/USER329 id/USER321_USER329
id/USER123 id/USER123 id/USER123_USER123
id/USER439 id/USER122 id/USER122_USER439
id/USER999 id/USER333 id/USER333_USER999
CodePudding user response:
Edit: approach is to apply a sort by row and then join the strings
#slightly changed example table
df = pd.DataFrame({
'Student1': ['id/USER321', 'id/USER123', 'id/USER439', 'id/USER999'],
'Student2': ['id/USER319', 'id/USER123', 'id/USER122', 'id/USER333'],
})
df['combined_id'] = df[['Student1','Student2']].apply(sorted, axis=1).str.join('_')
Output
CodePudding user response:
If there are only two student columns, finding row-wise min and max will work.
import pandas as pd
df = pd.DataFrame({
'Student1': ['id/USER321', 'id/USER123', 'id/USER439', 'id/USER999'],
'Student2': ['id/USER319', 'id/USER123', 'id/USER122', 'id/USER333'],
})
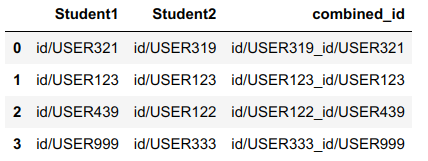
smaller = df.min(axis=1)
larger = df.max(axis=1)
df["combined_id"] = smaller "_" larger
df
# Student1 Student2 combined_id
#0 id/USER321 id/USER319 id/USER319_id/USER321
#1 id/USER123 id/USER123 id/USER123_id/USER123
#2 id/USER439 id/USER122 id/USER122_id/USER439
#3 id/USER999 id/USER333 id/USER333_id/USER999