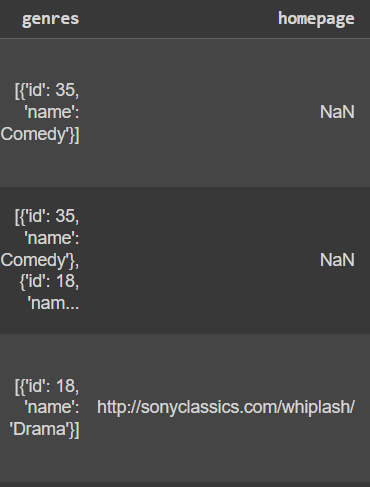
I have this column in my dataset. Tried to solve it by removing [ and { symbols from this as the whole column is a type string. Each character is a string including , : and spaces. while removing {. it only removes starting and ending not the in-between.
I want to extract only name values like 'Comedy', 'Thriller', ect.
CodePudding user response:
import numpy as np
import pandas as pd
import re
df = pd.DataFrame([["[{'id': 35, 'name': 'Comedy'}]", np.NaN], ["[{'id': 35, 'name': 'Comedy'}]", np.NaN]], columns=['genres', 'homepage'])
df['genres'] = df.apply(lambda x: re.search(r"'name':\s*'(.*)'", x['genres'], re.DOTALL).group(1), axis=1)
print(df)
Result:
genres homepage
0 Comedy NaN
1 Comedy NaN
UPDATE:
If you have rows that contains more than a genre, you can extract all genres using this:
import numpy as np
import pandas as pd
import json
def get_genres(string):
string = string.replace("\'", "\"")
j = json.loads(string)
genres = [obj['name'] for obj in j]
return ','.join(genres) # use `return genres[0]` if you want only the first genre found
df = pd.DataFrame([["[{'id': 35, 'name': 'Comedy'}, {'id': 18, 'name': 'Drama'}]", np.NaN], ["[{'id': 35, 'name': 'Comedy'}]", np.NaN]], columns=['genres', 'homepage'])
df['genres'] = df['genres'].apply(get_genres)
print(df)
Result:
genres homepage
0 Comedy,Drama NaN
1 Comedy NaN
CodePudding user response:
def convt(str):
return eval(str)
df['genre'] = df['genre'].apply(convt)