SQL optimization problem, which of the two solutions below is the most efficient?
I have the table from the image, I need to group the data by CPF and date and know if the CPFs had at least one login_ok = true on a specific date. Both solutions below satisfy my need but the goal is to find the best query.
We can have multiple login_ok = true and login_ok = false for CPFs on a specific date. I just need to know if there was at least one login_ok = true
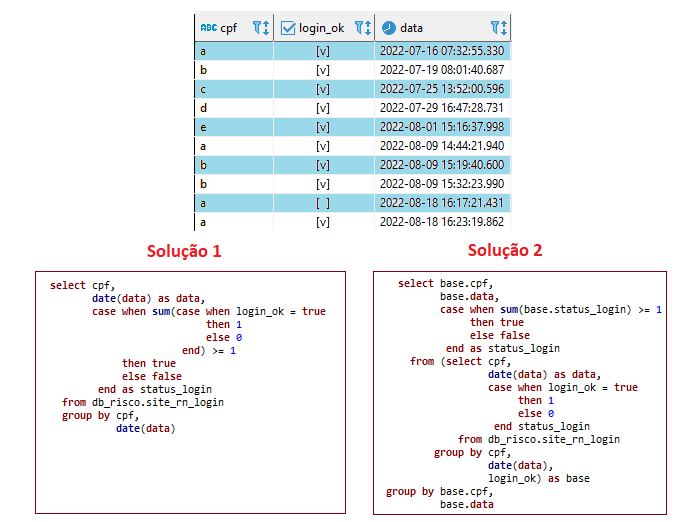
I already have two solutions, I want to discuss how to make another more efficient
CodePudding user response:
Maybe this would work for your problem:
SELECT
t2.CPF,
t2.data
FROM (
SELECT
CPF,
date(data) AS data
from db_risco.site_rn_login
WHERE login_ok
) t2
GROUP BY 1,2
ORDER BY t2.data
DISTINCT would also work, and I doubt it would pose any performance threat in your case. Usually it evals expressions (like date(data)) before checking for uniqueness.
By using a subquery, in this case, you can select upfront which CPFs to include and then extract date. Finally you'd group by on a quite smaller number os lines, since those were previously selected.
CodePudding user response:
PostgreSQL has the function BOOL_OR to check whether the expression is true for at least one row. It is likely to be optimised for this kind of task.
select cpf, date(data) as data, bool_or(login_ok) as status_login
from db_risco.site_rn_login
group by cpf, date(data);
An index on (cpf, date(data)) or even on (cpf, date(data), login_ok) could help speed up the query.
On a side note: You may also want to order your results with ORDER BY. Don't rely on GROUP BY doing this. The order of the rows resulting from a query is arbitrary without a GROUP BY clause.