My file input is a csv containing two columns, pop and year;
year is an integer counting up from 0 to 67 in order. pop is a float showing the population for that year.
import sklearn.linear_model as sk
import matplotlib.pyplot as plt
df = pd.read_csv("PopulationData.csv")
regression = sk.LinearRegression()
regression.fit(df[['pop']],df['year'])
plt.scatter(df['pop'],df['year'])
plt.plot(df[['pop']],regression.predict(df[['pop']]),color="red",linewidth=3)
plt.show()
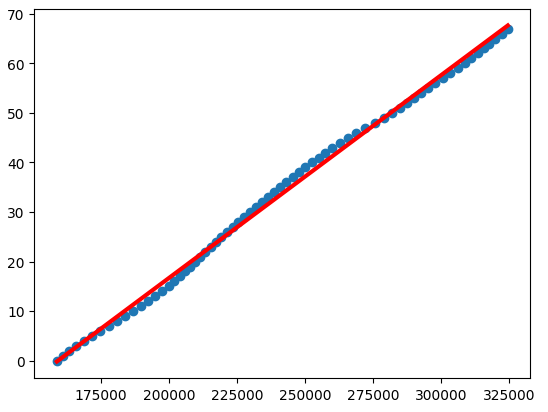
This code works for showing the input data from PopulationData.csv. However, I can't figure out how to have it predict the population from year 68 to 150 or any arbitrary number outside of the input file.
the psuedo code that I want to accomplish is this:
regression.predict([[68-150]])
#OR SOMETHING LIKE THIS
plt.plot(df[['pop']],regression.predict(df[[68-150]]),color="red",linewidth=3)
CodePudding user response:
Your code is using population to predict year, when you probably want the opposite. Switching the two should solve your issue:
import sklearn.linear_model as sk
import matplotlib.pyplot as plt
df = pd.read_csv("PopulationData.csv")
regression = sk.LinearRegression()
regression.fit(df[['year']],df['pop'])
plt.scatter(df['year'],df['pop'])
plt.plot(df[['year']],regression.predict(df[['year']]),color="red",linewidth=3)
plt.show()
# Predict on new data
pred = regression.predict(np.arange(68, 151).reshape(-1, 1))