Manipulate this DataFrame to become single row on multiples columns based on increasing price, any help to do that with pandas or numpy or list dict whatever and needs to be fast its real time snapshot i was trying to do with function and df.apply(lambad
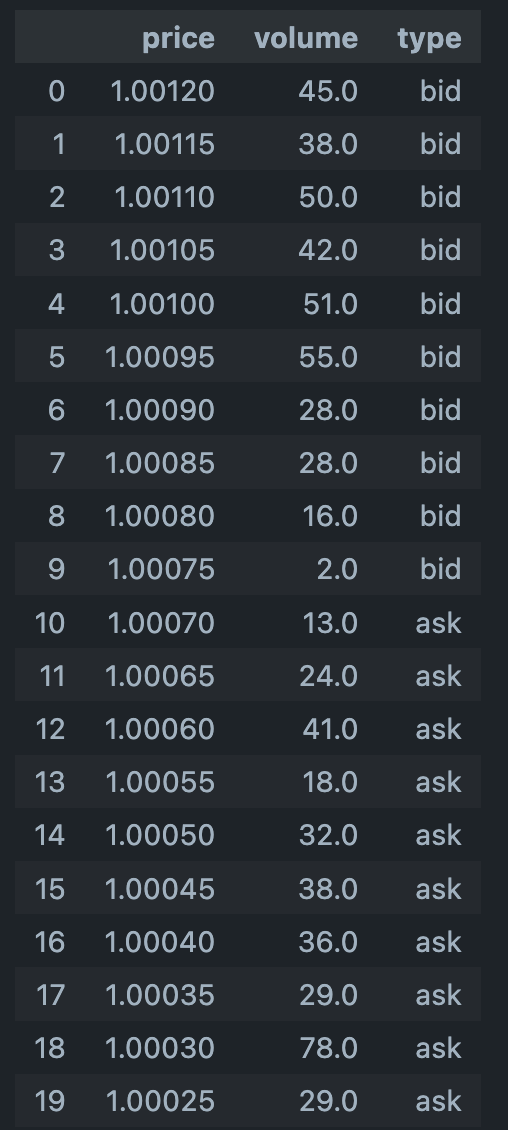
Follow the full dataframe
pd.DataFrame({'price': {0: 1.0012, 1: 1.00115, 2: 1.0011, 3: 1.00105, 4: 1.001, 5: 1.00095, 6: 1.0009, 7: 1.00085, 8: 1.0008, 9: 1.00075, 10: 1.0007, 11: 1.00065, 12: 1.0006, 13: 1.00055, 14: 1.0005, 15: 1.00045, 16: 1.0004, 17: 1.00035, 18: 1.0003, 19: 1.00025},'volume': {0: 45.0, 1: 38.0, 2: 50.0, 3: 42.0, 4: 51.0, 5: 55.0, 6: 28.0, 7: 28.0, 8: 16.0, 9: 2.0, 10: 13.0, 11: 24.0, 12: 41.0, 13: 18.0, 14: 32.0, 15: 38.0, 16: 36.0, 17: 29.0, 18: 78.0, 19: 29.0}, 'type': {0: 'bid', 1: 'bid', 2: 'bid', 3: 'bid', 4: 'bid', 5: 'bid', 6: 'bid', 7: 'bid', 8: 'bid', 9: 'bid', 10: 'ask', 11: 'ask', 12: 'ask', 13: 'ask', 14: 'ask', 15: 'ask', 16: 'ask', 17: 'ask', 18: 'ask', 19: 'ask'}})
for example, the beginning is on index 9 and 10 I need to make single row on multi columns
get the index based on increasing price, 9 columns will become price_ask_1 and index 10 price_bid_1 and volume_ask_1 and volume_bid_1 so on
['price_bid_1', 'price_ask_1', 'volume_bid_1', 'volume_ask_1','price_bid_2', 'price_ask_2', 'volume_bid_2', 'volume_ask_2']
until the last row in this case is 20
CodePudding user response:
For one row DataFrame with flatten MultiIndex use GroupBy.cumcount with DataFrame.stack - ouput is Series, then Series.to_frame with transpose, change ordering of columns and last flatten in map:
df = df.iloc[9:]
print (df)
price volume type
9 1.00075 2.0 bid
10 1.00070 13.0 ask
11 1.00065 24.0 ask
12 1.00060 41.0 ask
13 1.00055 18.0 ask
14 1.00050 32.0 ask
15 1.00045 38.0 ask
16 1.00040 36.0 ask
17 1.00035 29.0 ask
18 1.00030 78.0 ask
19 1.00025 29.0 ask
df1 = (df.set_index([df.groupby('type').cumcount().add(1), 'type'])
.stack()
.to_frame()
.T
.sort_index(level=[0, 2, 1], ascending=[True, True, False],axis=1))
df1.columns = df1.columns.map(lambda x: f'{x[2]}_{x[1]}_{x[0]}')
print(df1)
price_bid_1 price_ask_1 volume_bid_1 volume_ask_1 price_ask_2 \
0 1.00075 1.0007 2.0 13.0 1.00065
volume_ask_2 price_ask_3 volume_ask_3 price_ask_4 volume_ask_4 ... \
0 24.0 1.0006 41.0 1.00055 18.0 ...
price_ask_6 volume_ask_6 price_ask_7 volume_ask_7 price_ask_8 \
0 1.00045 38.0 1.0004 36.0 1.00035
volume_ask_8 price_ask_9 volume_ask_9 price_ask_10 volume_ask_10
0 29.0 1.0003 78.0 1.00025 29.0
[1 rows x 22 columns]