Have the following dataframe:
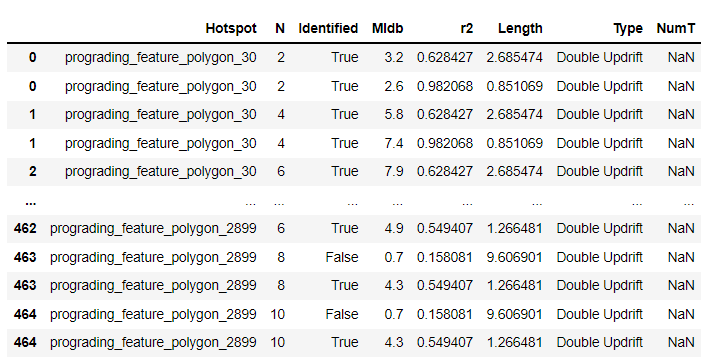
Sometimes the index is duplicate and then I want to change the value in the column 'Hotspot'. So prograding_feature_polygon_30 should be changed to prograding_feature_polygon_30_1 and the second on index 0 to prograding_feature_polygon_30_2.
The same on index 1, so again the values should be changed to prograding_feature_polygon_30_1 and prograding_feature_polygon_30_2. And so on...
Indexes are not always duplicate and if not, the value in Hotspot should remain the same. Anyone knows an easy way to do this?
Regards,
Dante
CodePudding user response:
Data sample
import pandas as pd
import numpy as np
df = pd.DataFrame({'a': np.repeat([*'ABCD'],[2,1,3,1]),
'b': [*range(7)]},
index=np.repeat([*range(4)],[2,1,3,1]))
print(df)
a b
0 A 0
0 A 1
1 B 2
2 C 3
2 C 4
2 C 5
3 D 6
Problem
For each duplicate in the index, we want to add a consecutive number to the values in column a. So, A_1, A_2 for index value 0, and C_1, C_2, C_3 for index value 2. Values without duplicates (1 and 3) should be unaffected.
Solution
df.a = np.where(df.index.duplicated(keep=False),
df.a '_' df.groupby(level=0).cumcount().add(1).astype(str),
df.a)
print(df)
a b
0 A_1 0
0 A_2 1
1 B 2
2 C_1 3
2 C_2 4
2 C_3 5
3 D 6
Explanation
- Use
df.index.duplicatedwith paramkeep=Falseto get an array withTruefor duplicates,Falsefor non-duplicates. - Use this array inside
np.where. IfTrue, we wantdf.a consecutive number, else simplydf.a. - Use
df.groupbyon the index, and apply.cumcountto enumerate items per group.add(1)to start at1, instead of0. Finally, useastype(str), in view of the concatenation withdf.a.